Redis 数据结构浅析
相关代码基于 Redis 版本 5.0.14 源码
RedisObject
RedisObject 结构体是在 server.h 文件中定义的,主要功能是用来保存键值对中的值。这个结构一共定义了 4 个元数据和一个指针。
- type:redisObject 的数据类型,是应用程序在 Redis 中保存的数据类型,包括 String、List、Hash 等
- encoding:redisObject 的编码类型,是 Redis 内部实现各种数据类型所用的数据结构。
- lru:redisObject 的 LRU 时间。
- refcount:redisObject 的引用计数。
- ptr:指向值的指针。
/* Objects encoding. Some kind of objects like Strings and Hashes can be
* internally represented in multiple ways. The 'encoding' field of the object
* is set to one of this fields for this object. */
#define OBJ_ENCODING_RAW 0 /* Raw representation */
#define OBJ_ENCODING_INT 1 /* Encoded as integer */
#define OBJ_ENCODING_HT 2 /* Encoded as hash table */
#define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */
#define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */
#define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */
#define OBJ_ENCODING_INTSET 6 /* Encoded as intset */
#define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
#define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */
#define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */
#define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */
#define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */
#define LRU_BITS 24
#define LRU_CLOCK_MAX ((1<<LRU_BITS)-1) /* Max value of obj->lru */
#define LRU_CLOCK_RESOLUTION 1000 /* LRU clock resolution in ms */
...
struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
};
String
Redis 设计了简单动态字符串 (Simple Dynamic String,SDS) 的结构,用来表示字符串。相比于 C 语言中的字符串实现,SDS 这种字符串的实现方式,会提升字符串的操作效率,并且可以用来保存二进制数据。
SDS 结构设计
SDS 结构里包含了一个字符数组 buf,用来保存实际数据。同时,SDS 结构里还包含了三个元数据,分别是字符数组现有长度 len、分配给字符数组的空间长度 alloc,以及 SDS 类型 flags。同时 SDS 设计了不同的结构头(即不同类型),能灵活保存不同大小的字符串,从而有效节省内存空间。
typedef char *sds;
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
SDS 对比 Char*
- C 语言中使用 char* 实现字符串的不足,主要是因为使用“\0”表示字符串结束,操作时需遍历字符串,效率不高,并且无法完整表示包含“\0”的数据,因而这就无法满足 Redis 的需求。
- Redis 中字符串的设计思想与实现方法。Redis 专门设计了 SDS 数据结构,在字符数组的基础上,增加了字符数组长度和分配空间大小等元数据。这样一来,需要基于字符串长度进行的追加、复制、比较等操作,就可以直接读取元数据,效率也就提升了。而且,SDS 不通过字符串中的“\0”字符判断字符串结束,而是直接将其作为二进制数据处理,可以用来保存图片等二进制数据。
- SDS 中是通过设计不同 SDS 类型来表示不同大小的字符串,并使用
__attribute__ ((__packed__))这个编程小技巧,来实现紧凑型内存布局,达到节省内存的目的。
另外 Redis 在操作 SDS 时,为了避免频繁操作字符串时,每次「申请、释放」内存的开销,还做了这些优化:
- 内存预分配:SDS 扩容,会多申请一些内存(小于 1MB 翻倍扩容,大于 1MB 按 1MB 扩容)
- 多余内存不释放:SDS 缩容,不释放多余的内存,下次使用可直接复用这些内存
#define SDS_MAX_PREALLOC (1024*1024)
sds sdsMakeRoomFor(sds s, size_t addlen) {
...
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
reqlen = newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
...
}
ZipList(List / Hashes / ZSet)
Redis 中的 ZipList 数据结构是特殊编码的双向链表,它以紧凑的顺序布局存储元素,无需为每个元素单独分配内存,从而减少了内存开销。ZipList 尤其适用于元素数量有限的小型集合,主要用于优化数据量较小的 List、Hash 和 Sorted Set。所有操作都是通过偏移量完成的
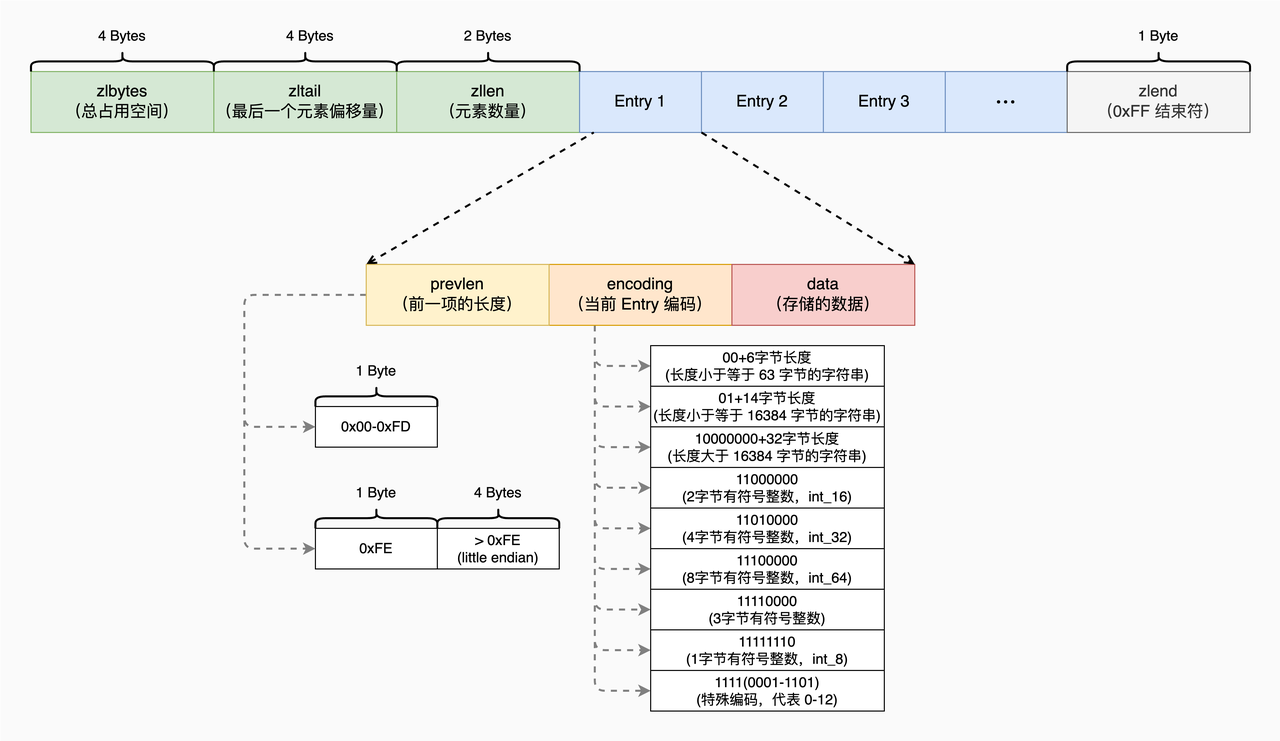
主要操作
查找操作
循环遍历直到 zlend,根据不同的 Encoding 去解析对应的 Entry 直到找到需要的数据。
/* Find pointer to the entry equal to the specified entry. Skip 'skip' entries
* between every comparison. Returns NULL when the field could not be found. */
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip) {
...
while (p[0] != ZIP_END) {
...
unsigned int prevlensize, encoding, lensize, len;
unsigned char *q;
ZIP_DECODE_PREVLENSIZE(p, prevlensize);
ZIP_DECODE_LENGTH(p + prevlensize, encoding, lensize, len);
q = p + prevlensize + lensize;
if (skipcnt == 0) {
/* Compare current entry with specified entry */
if (ZIP_IS_STR(encoding)) {
...
} else {
/* Find out if the searched field can be encoded. Note that
* we do it only the first time, once done vencoding is set
* to non-zero and vll is set to the integer value. */
if (vencoding == 0) {
if (!zipTryEncoding(vstr, vlen, &vll, &vencoding)) {
/* If the entry can't be encoded we set it to
* UCHAR_MAX so that we don't retry again the next
* time. */
vencoding = UCHAR_MAX;
}
/* Must be non-zero by now */
assert(vencoding);
}
/* Compare current entry with specified entry, do it only
* if vencoding != UCHAR_MAX because if there is no encoding
* possible for the field it can't be a valid integer. */
if (vencoding != UCHAR_MAX) {
long long ll = zipLoadInteger(q, encoding);
if (ll == vll) {
return p;
}
}
}
...
}
...
}
}
插入操作
- 找到插入位置
- 尝试编码数据,计算所需空间
- 更新前后 Entry 的 prevlen 等数据(如果有)
- 扩容压缩表空间,申请内存空间并移动压缩表
- 写入新 Entry
// 具体代码参考下列函数
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/ziplist.c#L755
/* Insert item at "p". */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen)
插入操作会由于 ZipList 对 prevlen 的编码不同,导致需要对插入位置后的元素的 prevlen 进行更新,使其等于插入条目的长度。可能出现的情况是,这个长度无法用 1 个字节编码,因此下一个条目需要增大一些,以容纳 5 字节编码的 prevlen。这会导致重新分配和 memmove。如果后续的 Entry 恰好在更新总长度后又超出了 ZIP_BIG_PREVLEN,就会发生级联扩容。插入位置后续节点向后移动。
删除操作
- 计算删除节点的大小
- 让删除节点的后面节点往前面覆盖
- 释放多余的空间
// 具体代码参考下列函数
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/ziplist.c#L690
/* Delete "num" entries, starting at "p". Returns pointer to the ziplist. */
unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num)
删除操作也一样,可能会因为 prevlen 的编码问题引发级联更新。删除 指定 Entry 时,其后续的节点级联更新向前移动。
级联更新
/* When an entry is inserted, we need to set the prevlen field of the next
* entry to equal the length of the inserted entry. It can occur that this
* length cannot be encoded in 1 byte and the next entry needs to be grow
* a bit larger to hold the 5-byte encoded prevlen. This can be done for free,
* because this only happens when an entry is already being inserted (which
* causes a realloc and memmove). However, encoding the prevlen may require
* that this entry is grown as well. This effect may cascade throughout
* the ziplist when there are consecutive entries with a size close to
* ZIP_BIG_PREVLEN, so we need to check that the prevlen can be encoded in
* every consecutive entry.
*
* Note that this effect can also happen in reverse, where the bytes required
* to encode the prevlen field can shrink. This effect is deliberately ignored,
* because it can cause a "flapping" effect where a chain prevlen fields is
* first grown and then shrunk again after consecutive inserts. Rather, the
* field is allowed to stay larger than necessary, because a large prevlen
* field implies the ziplist is holding large entries anyway.
*
* The pointer "p" points to the first entry that does NOT need to be
* updated, i.e. consecutive fields MAY need an update. */
unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p)
根据情况将压缩表扩容,元素后移(插入操作)。或元素迁移,压缩表缩容(删除操作)。
优缺点
ZipList 设计的初衷就是「节省内存」,在存储数据时,把内存利用率发挥到了极致
- 数字按整型编码存储,比直接当字符串存内存占用少
- 数据长度字段,会根据内容的大小选择最小的长度编码
- 甚至对于极小的数据,干脆把内容直接放到了长度字段中(前几个位表示长度,后几个位存数据)
但 ZipList 的劣势也很明显:
- 寻找元素只能挨个遍历,存储过长数据,或存储的元素数量较多的情况下,查询性能很低。
- 可能会导致级联更新的问题,即每个元素中保存了上一个元素的长度(为了方便反向遍历),这会导致上一个元素内容发生修改,长度超过了原来的编码长度,下一个元素的内容也要跟着变,重新分配内存,进而就有可能再次引起下一级的变化,一级级更新下去,频繁申请内存。
QuickList(List)
先前介绍 ZipList 的内容中,阐述了 ZipList 的一些问题。Redis 先是在 3.0 版本中设计实现了 QuickList。QuickList 结构在 ZipList 基础上,使用链表将 ZipList 串联起来,链表的每个元素就是一个 ZipList。这种设计减少了数据插入时内存空间的重新分配,以及内存数据的拷贝。同时,QuickList 限制了每个节点上 ZipList 的大小,一旦一个 ziplist 过大,就会采用新增 QuickList 节点的方法。QuickList 的设计,其实是结合了链表和 ZipList 各自的优势。简单来说,一个 QuickList 就是一个链表,而链表中的每个元素又是一个 ZipList。
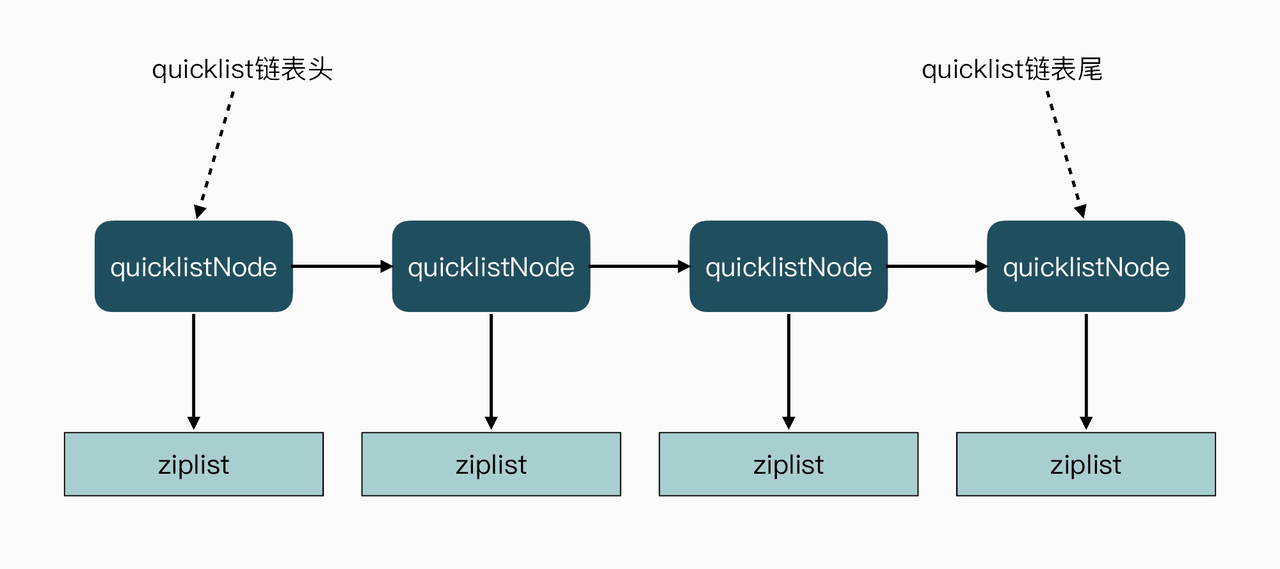
设计与实现
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist.
* 'count' is the number of total entries.
* 'len' is the number of quicklist nodes.
* 'compress' is: -1 if compression disabled, otherwise it's the number
* of quicklistNodes to leave uncompressed at ends of quicklist.
* 'fill' is the user-requested (or default) fill factor. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; /* 指向的 ZipList
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
QuickList采用了链表结构,所以当插入一个新的元素时,QuickList 首先就会检查插入位置的 ZipList 是否能容纳该元素,这是通过 _quicklistNodeAllowInsert 函数来完成判断的。
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
if (unlikely(!node))
return 0;
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
/* new_sz overestimates if 'sz' encodes to an integer type */
unsigned int new_sz = node->sz + sz + ziplist_overhead;
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
/* when we return 1 above we know that the limit is a size limit (which is
* safe, see comments next to optimization_level and SIZE_SAFETY_LIMIT) */
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
else if ((int)node->count < fill)
return 1;
else
return 0;
}
这里还有个fill字段,它的含义是每个quicknode的节点最大容量,不同的数值有不同的含义,默认是-2,当然也可以配置为其他数值,具体数值含义如下:
- -1: 每个quicklistNode节点的ziplist所占字节数不能超过4kb。(建议配置)
- -2: 每个quicklistNode节点的ziplist所占字节数不能超过8kb。(默认配置&建议配置)
- -3: 每个quicklistNode节点的ziplist所占字节数不能超过16kb。
- -4: 每个quicklistNode节点的ziplist所占字节数不能超过32kb。
- -5: 每个quicklistNode节点的ziplist所占字节数不能超过64kb。
- 任意正数: 表示:ziplist结构所最多包含的entry个数,最大为215215。
因此函数会检查需要插入的元素大小在插入节点后,节点的大小是否符合相关的 optimization_level 所要求的大小。
常用操作
插入
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/quicklist.c#L358
/* Insert a new entry before or after existing entry 'entry'.
*
* If after==1, the new value is inserted after 'entry', otherwise
* the new value is inserted before 'entry'. */
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after)
- 当前 QuickList 为空,则先初始化并创建第一个节点。
- 确定当前 QuickListNode 指向的 ZipList 是否有空间插入。如果是尾插,同时检查后继节点是否有空间插入。如果是头插,则同时检查前序节点是否有空间插入
- 如果当前节点未满,则根据要求从头部插入或尾部插入到指定位置。
- 如果当前节点满,需要尾插,但后继节点不为空且未满,则在后继节点进行头插。
- 如果当前节点满,需要头插,但前序节点不为空且未满,则在前序节点进行尾插。
- 如果当前节点满,并且前后节点都不为空且满的情况下,根据插入位置在合适位置创建新节点进行插入。
- 不满足上述情况,则需要把当前节点分裂成两个新节点,一般用于插入到当前节点 ZipList中间某个位置时。
删除
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/quicklist.c#L625
/* Delete one entry from list given the node for the entry and a pointer
* to the entry in the node.
*
* Note: quicklistDelIndex() *requires* uncompressed nodes because you
* already had to get *p from an uncompressed node somewhere.
*
* Returns 1 if the entire node was deleted, 0 if node still exists.
* Also updates in/out param 'p' with the next offset in the ziplist. */
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,
unsigned char **p)
删除操作相对简单很多,直接从对应的 QuickListNode 指向的 ZipList 中删除对应的数据,如果删除后 ZipList 为空,则回收整个 QuickListNode。
ListPack(Stream)
QuickList 使用 QuickListNode 结构指向每个 ZipList,增加了内存开销。为了减少内存开销,并进一步避免 ZipList 连锁更新问题,Redis 在 5.0 版本中,就设计实现了 ListPack 结构。ListPack 结构沿用了 ziplist 紧凑型的内存布局,把每个元素都紧挨着放置。ListPack 中每个列表项不再包含前一项的长度了,因此当某个列表项中的数据发生变化,导致列表项长度变化时,其他列表项的长度是不会受影响的,因而这就避免了 ZipList 面临的连锁更新问题。
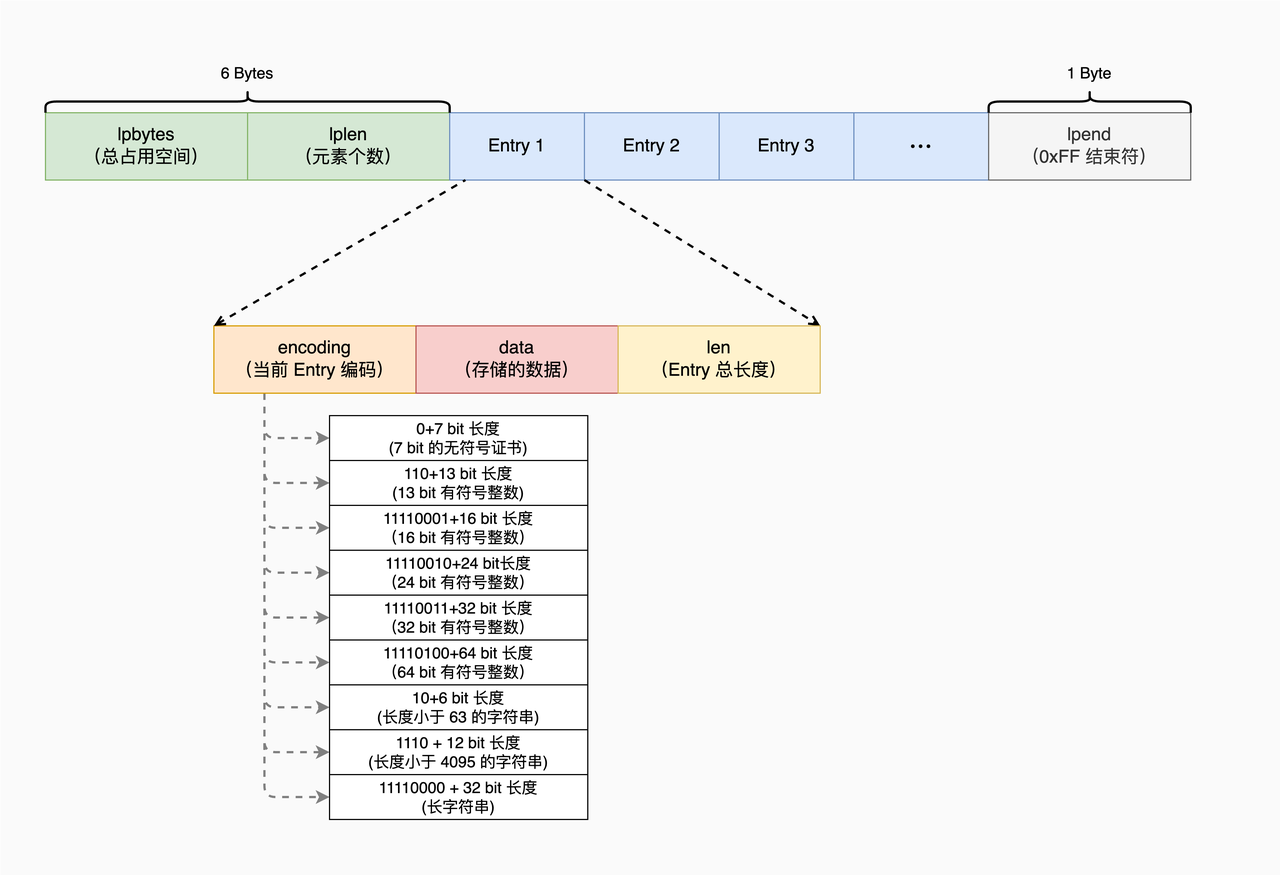
在 listpack 中,因为每个列表项只记录自己的长度,而不会像 ziplist 中的列表项那样,会记录前一项的长度。所以,当我们在 listpack 中新增或修改元素时,实际上只会涉及每个列表项自己的操作,而不会影响后续列表项的长度变化,这就避免了连锁更新。
设计与实现
ListPack 创建
/* Create a new, empty listpack.
* On success the new listpack is returned, otherwise an error is returned. */
unsigned char *lpNew(void) {
unsigned char *lp = lp_malloc(LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
Entry BackLen 解析逻辑
Entry-len 最多包含 5 个字节,其中 entry-len 每个字节的最高位,是用来表示当前字节是否为 entry-len 的最后一个字节,这里存在两种情况,分别是:
- 最高位为 1,表示 entry-len 还没有结束,当前字节的左边字节仍然表示 entry-len 的内容;
- 最高位为 0,表示当前字节已经是 entry-len 最后一个字节了。
而 entry-len 每个字节的低 7 位,则记录了实际的长度信息。这里你需要注意的是,entry-len 每个字节的低 7 位采用了大端模式存储,也就是说,entry-len 的低位字节保存在内存高地址上。
/* Decode the backlen and returns it. If the encoding looks invalid (more than
* 5 bytes are used), UINT64_MAX is returned to report the problem. */
uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0;
uint64_t shift = 0;
do {
val |= (uint64_t)(p[0] & 127) << shift;
if (!(p[0] & 128)) break;
shift += 7;
p--;
if (shift > 28) return UINT64_MAX;
} while(1);
return val;
}
有了特殊的 entry-len 编码格式,使得 ListPack 在 Entry 仅记录自身的长度的情况下,支持正向和反向遍历。
Hashes(Hashes / Set / ZSet)
Redis 为我们提供了一个经典的 Hash 表实现方案。针对哈希冲突,Redis 采用了链式哈希,在不扩容哈希表的前提下,将具有相同哈希值的数据链接起来,以便这些数据在表中仍然可以被查询到;对于 rehash 开销,Redis 实现了渐进式 rehash 设计,进而缓解了 rehash 操作带来的额外开销对系统的性能影响。
压缩表存储
#define OBJ_HASH_MAX_ZIPLIST_ENTRIES 512
#define OBJ_HASH_MAX_ZIPLIST_VALUE 64
在哈希表元素数量小于 512 个且元素大小小于 64 字节时,哈希表会借助压缩表结构进行存储。Redis 会根据获取到的 RedisObject 的类型,通过不同的方法适配压缩表和 Dict 的操作以实现相同的逻辑
Dict 结构设计
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
- Hash 表被定义为一个二维数组(dictEntry **table),这个数组的每个元素是一个指向哈希项(dictEntry)的指针,即数组里的每个元素是一个哈希桶。
- Redis 在每个 dictEntry 的结构设计中,除了包含指向键和值的指针,还包含了指向下一个哈希项的指针。(链地址法解决哈希冲突)。
渐进式 Rehash
Rehash 过程
- Redis 准备了两个哈希表,用于 rehash 时交替保存数据。
- 在正常服务请求阶段,所有的键值对写入哈希表 ht0。
- 当进行 rehash 时,键值对被迁移到哈希表 ht1中。
- 迁移完成后,ht0的空间会被释放,并把 ht1的地址赋值给 ht0,ht1的表大小设置为 0。这样一来,又回到了正常服务请求的阶段,ht0接收和服务请求,ht1作为下一次 rehash 时的迁移表。
Rehash 触发条件
- 不处于 Rehash 过程中。
- ht0 承载的元素个数已经超过了 ht0 的大小,同时 Hash 表可以进行扩容。即负载因子大于等于 1 小于 5 且
dict_can_resize=1时会触发扩容并 Rehash - ht0 承载的元素个数,是 ht0 的大小的 dict_force_resize_ratio 倍,其中,dict_force_resize_ratio 的默认值是 5。即负载因子大于 5 时会触发扩容并 Rehash。
- ht0 承载的元素个数,是 ht0 的大小的 1/10 时。即负载因子小于 0.1 时会触发缩容并 Rehash。
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
/* Hash table parameters */
#define HASHTABLE_MIN_FILL 10 /* Minimal hash table fill 10% */
int htNeedsResize(dict *dict) {
long long size, used;
size = dictSlots(dict);
used = dictSize(dict);
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
dict_can_resize 变量控制,如果当前没有 RDB 子进程,并且也没有 AOF 子进程,可以触发 Rehash。即对应了 Redis 当前没有执行 RDB 快照和没有进行 AOF 重写的场景。
/* This function is called once a background process of some kind terminates,
* as we want to avoid resizing the hash tables when there is a child in order
* to play well with copy-on-write (otherwise when a resize happens lots of
* memory pages are copied). The goal of this function is to update the ability
* for dict.c to resize the hash tables accordingly to the fact we have o not
* running childs. */
void updateDictResizePolicy(void) {
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1)
dictEnableResize();
else
dictDisableResize();
}
Rehash 扩容按照当前哈希表容量的 2 的倍数进行扩容,但是实际是找到 DICT_HT_INITIAL_SIZE^2 大于期望大小的值,DICT_HT_INITIAL_SIZE 默认为 4
/* Expand or create the hash table */
int dictExpand(dict *d, unsigned long size)
{
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* Rehashing to the same table size is not useful. */
if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}
/* Our hash table capability is a power of two */
static unsigned long _dictNextPower(unsigned long size)
{
unsigned long i = DICT_HT_INITIAL_SIZE;
if (size >= LONG_MAX) return LONG_MAX + 1LU;
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
Rehash 实现细节
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
- 该函数会执行一个循环,根据要进行键拷贝的 bucket 数量 n,依次完成这些 bucket 内部所有键的迁移。当然,如果 ht0哈希表中的数据已经都迁移完成了,键拷贝的循环也会停止执行。
- 在完成了 n 个 bucket 拷贝后,dictRehash 函数的第二部分逻辑,就是判断 ht0表中数据是否都已迁移完。如果都迁移完了,那么 ht0的空间会被释放。因为 Redis 在处理请求时,代码逻辑中都是使用 ht0,所以当 rehash 执行完成后,虽然数据都在 ht1中了,但 Redis 仍然会把 ht1赋值给 ht0,以便其他部分的代码逻辑正常使用。
- 在 ht1赋值给 ht0后,它的大小就会被重置为 0,等待下一次 rehash。与此同时,全局哈希表中的 rehashidx 变量会被标为 -1,表示 rehash 结束。
其中 rehashidx 变量表示的是当前 rehash 在对哪个 bucket 做数据迁移。比如,当 rehashidx 等于 0 时,表示对 ht0中的第一个 bucket 进行数据迁移;当 rehashidx 等于 1 时,表示对 ht0中的第二个 bucket 进行数据迁移,以此类推。而 dictRehash 函数的主循环,首先会判断 rehashidx 指向的 bucket 是否为空,如果为空,那就将 rehashidx 的值加 1,检查下一个 bucket。同时,渐进式 rehash 在执行时设置了一个变量 empty_visits,用来表示已经检查过的空 bucket,当检查了一定数量的空 bucket 后,这一轮的 rehash 就停止执行,转而继续处理外来请求,避免了对 Redis 性能的影响。
SortedSet(ZSet)
有序集合(Sorted Set)是 Redis 中一种重要的数据类型,它本身是集合类型,同时也可以支持集合中的元素带有权重,并按权重排序。
压缩表存储
#define OBJ_ZSET_MAX_ZIPLIST_ENTRIES 128
#define OBJ_ZSET_MAX_ZIPLIST_VALUE 64
在 SortedSet 元素数量小于 128 个且元素大小小于 64 字节时,SortedSet 会借助压缩表结构进行存储。Redis 会根据获取到的 RedisObject 的类型,通过不同的方法适配压缩表和 ZSet 的操作以实现相同的逻辑
Sorted Set 基本结构
typedef struct zset {
dict *dict; // 哈希表索引
zskiplist *zsl; // 跳表实现范围查
} zset;
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头尾节点
unsigned long length; // 链表长度
int level; // 当前 level
} zskiplist;
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
sds ele; // Member
double score; // Score
struct zskiplistNode *backward; // 后继指针
// 节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
从上述结构中可以看出,Sorted Set 能支持范围查询,这是因为它的核心数据结构设计采用了跳表,而它又能以常数复杂度获取元素权重,这是因为它同时采用了哈希表进行索引。
跳表的设计与实现
跳表其实是一种有序链表 + 多层索引的结构,用于优化范围查找。这种设计方法带来的好处是,当跳表从最高层开始进行查找时,由于每一层结点数都约是下一层结点数的一半,这种查找过程就类似于二分查找,查找复杂度可以降低到 O(logN)。
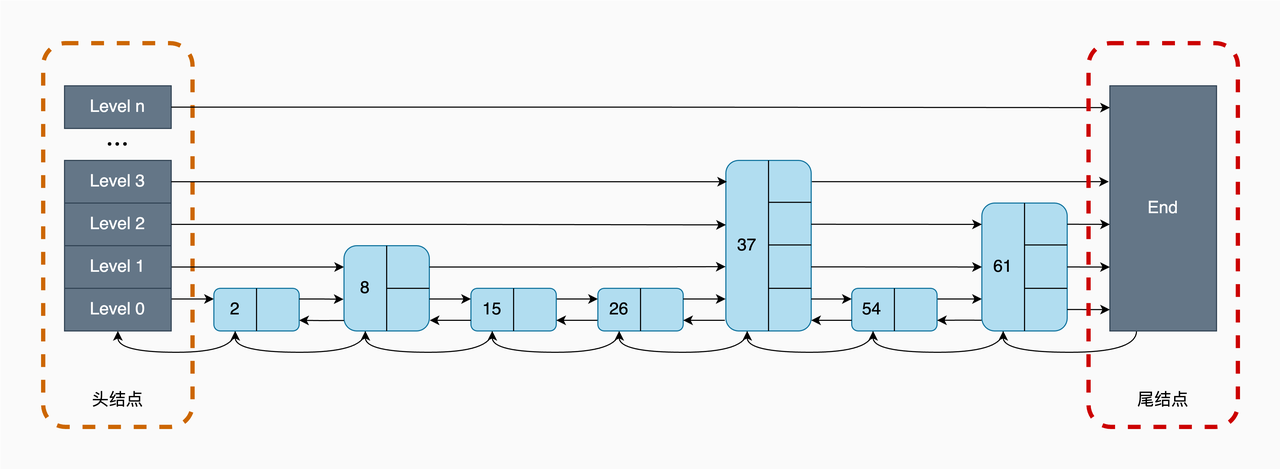
跳表结点层数设置
SkipList 的多层索引,采用「随机」的方式来构建,也就是说每次添加一个元素进来,要不要对这个元素建立「多层索引」?建立「几层索引」?都要通过「随机数」的方式来决定。每个元素在加入跳表的过程中都有一定概率在更高层创建索引。
#define ZSKIPLIST_MAXLEVEL 64 //最大层数为64
#define ZSKIPLIST_P 0.25 //随机数的值为0.25
int zslRandomLevel(void) {
//初始化层为1
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
这个预设「概率」决定了一个跳表的内存占用和查询复杂度:概率设置越低,层数越少,元素指针越少,内存占用也就越少,但查询复杂会变高,反之亦然。这也是 skiplist 的一大特点,可通过控制概率,进而控制内存和查询效率。
跳表和平衡二叉树对比
关于 Redis 的 ZSet 为什么用 SkipList 而不用平衡二叉树实现的问题,原因如下:
- SkipList 更省内存:25% 概率的随机层数,可通过公式计算出 SkipList 平均每个节点的指针数是 1.33 个,平衡二叉树每个节点指针是 2 个(左右子树)
- SkipList 操作更友好:SkipList 找到大于目标元素后,向后遍历链表即可,平衡树需要通过中序遍历方式来完成,实现也略复杂。二叉平衡树还和涉及到重新平衡操作,比较复杂。
- SkipList 更易实现和维护:扩展 SkipList 只需要改少量代码即可完成,平衡树维护起来更复杂。
插入节点
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
// 查找插入位置,会考虑 Score 和 SDS 字典序
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
// 获取索引层数
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
// 插入节点,维护前后节点跨度
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
删除节点
/* Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 修改每一层指针的指向
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
// 找到每一层要删除节点的前置节点
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
// 删除节点
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
}
return 0; /* not found */
}
哈希表结合跳表
- 哈希表存储 Member -> Score 的关系,获取 Score 复杂度为 O(1)
- 跳表根据 Score 按顺序存储 Member(Score + SDS 字典序),查找复杂度可以降低到 O(logN)。
- 但由于引入了哈希表,当进行插入删除操作的时候,会给操作带来额外的开销。例如:批量插入导致哈希表扩容 Rehash,批量范围删除导致哈希表的批量删除。
常见操作
插入
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/t_zset.c#L1317
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore)
SortedSet 的插入操作会根据实际类型进行:
- zsetAdd 函数会判定 Sorted Set 采用的是 ZipList 还是 SkipList 的编码方式。
- 如果为 ZipList 对象:
- 先查找对应元素,如果元素已存在:
- NX 插入:直接返回
- INCR 操作:增加 Score
- Score 变更时候先删除元素后重新插入
- 如果元素不存在,且非 XX 插入的情况下:
- 检查是否超出 SortedSet 使用 ZipList 存储的限制条件,超出则转换为跳表模式,否则直接插入
- 先查找对应元素,如果元素已存在:
- 如果为 zset 对象:
- 先查找对应元素(哈希表查找),如果元素已存在:
- NX 插入:直接返回
- INCR 操作:增加 Score
- Score 变更时候先更新跳表,然后更新哈希表
- 如果元素不存在,且非 XX 插入的情况下:
- 复制 SDS
- 将元素插入跳表
- 将元素插入哈希表
- 先查找对应元素(哈希表查找),如果元素已存在:
删除
ZREM/ZREMRANGEBYLEX/ZREMRANGEBYRANK/ZREMRANGEBYSCORE
// https://github.com/redis/redis/blob/704ba5f5b22ae1ecafbcfb7a3258311c27ff94ff/src/t_zset.c#L1434
/* Delete the element 'ele' from the sorted set, returning 1 if the element
* existed and was deleted, 0 otherwise (the element was not there). */
int zsetDel(robj *zobj, sds ele)
- zsetDel 函数会判定 Sorted Set 采用的是 ZipList 还是 SkipList 的编码方式。
- 如果为 ZipList 对象:
- 先查找对应元素,如果元素已存在:
- 从 ZipList 中删除对应 Entry
- 先查找对应元素,如果元素已存在:
- 如果为 zset 对象:
- 先查找对应元素(哈希表查找),如果元素已存在:
- 从哈希表中删除元素
- 从跳表中删除元素
- 检查哈希表时候需要缩容,如果需要则开始缩容。
- 先查找对应元素(哈希表查找),如果元素已存在:
压缩表跳表转换
/* Convert the sorted set object into a ziplist if it is not already a ziplist
* and if the number of elements and the maximum element size and total elements size
* are within the expected ranges. */
void zsetConvertToZiplistIfNeeded(robj *zobj, size_t maxelelen, size_t totelelen) {
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) return;
zset *zset = zobj->ptr;
if (zset->zsl->length <= server.zset_max_ziplist_entries &&
maxelelen <= server.zset_max_ziplist_value &&
ziplistSafeToAdd(NULL, totelelen))
{
zsetConvert(zobj,OBJ_ENCODING_ZIPLIST);
}
}
void zsetConvert(robj *zobj, int encoding) {
...
if (zobj->encoding == encoding) return;
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
...
zs = zmalloc(sizeof(*zs));
zs->dict = dictCreate(&zsetDictType,NULL);
zs->zsl = zslCreate();
...
while (eptr != NULL) {
score = zzlGetScore(sptr);
serverAssertWithInfo(NULL,zobj,ziplistGet(eptr,&vstr,&vlen,&vlong));
if (vstr == NULL)
ele = sdsfromlonglong(vlong);
else
ele = sdsnewlen((char*)vstr,vlen);
node = zslInsert(zs->zsl,score,ele);
serverAssert(dictAdd(zs->dict,ele,&node->score) == DICT_OK);
zzlNext(zl,&eptr,&sptr);
}
zfree(zobj->ptr);
zobj->ptr = zs;
zobj->encoding = OBJ_ENCODING_SKIPLIST;
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
unsigned char *zl = ziplistNew();
...
while (node) {
zl = zzlInsertAt(zl,NULL,node->ele,node->score);
next = node->level[0].forward;
zslFreeNode(node);
node = next;
}
zfree(zs);
zobj->ptr = zl;
zobj->encoding = OBJ_ENCODING_ZIPLIST;
...
}
主要还是根据压缩表存储的条件进行相互转换,根据输入输出的 Encoding,都是将输入的结构插入到重新创建的输出结构中,再将输入结构清理并释放内存空间。
小结
以上就是对 Redis 几大数据结构的浅析,Redis 作为一个高性能的内存 KV 库,其数据结构设计和实现都是非常值得学习的。每种数据结构都有其特点和适用场景,Redis 也根据不同的场景选择了不同的数据结构来实现,以达到最优的性能。