Go 调度器浅析 —— Goroutine 启动和执行
基础知识
进程、线程、协程
- 进程是指计算机内存中一个独立的、正在执行的程序实例。进程包含程序运行所需的整个运行时环境,包括程序代码、数据、系统资源和执行上下文。在操作系统中,进程是资源拥有的基本单位。
- 线程是计算机操作系统进程中的一个基本执行单元。线程比进程更轻量,允许多个指令序列在同一进程内同时运行,共享进程的资源、内存空间和其他属性。在操作系统中,线程是独立调度的基本单位,
- 协程是定义在用户空间的调度单元,协程比线程更轻量,可以随意暂停或恢复执行。协程相关的资源、堆栈、调度都由协程调度器进行管理。
调度模型
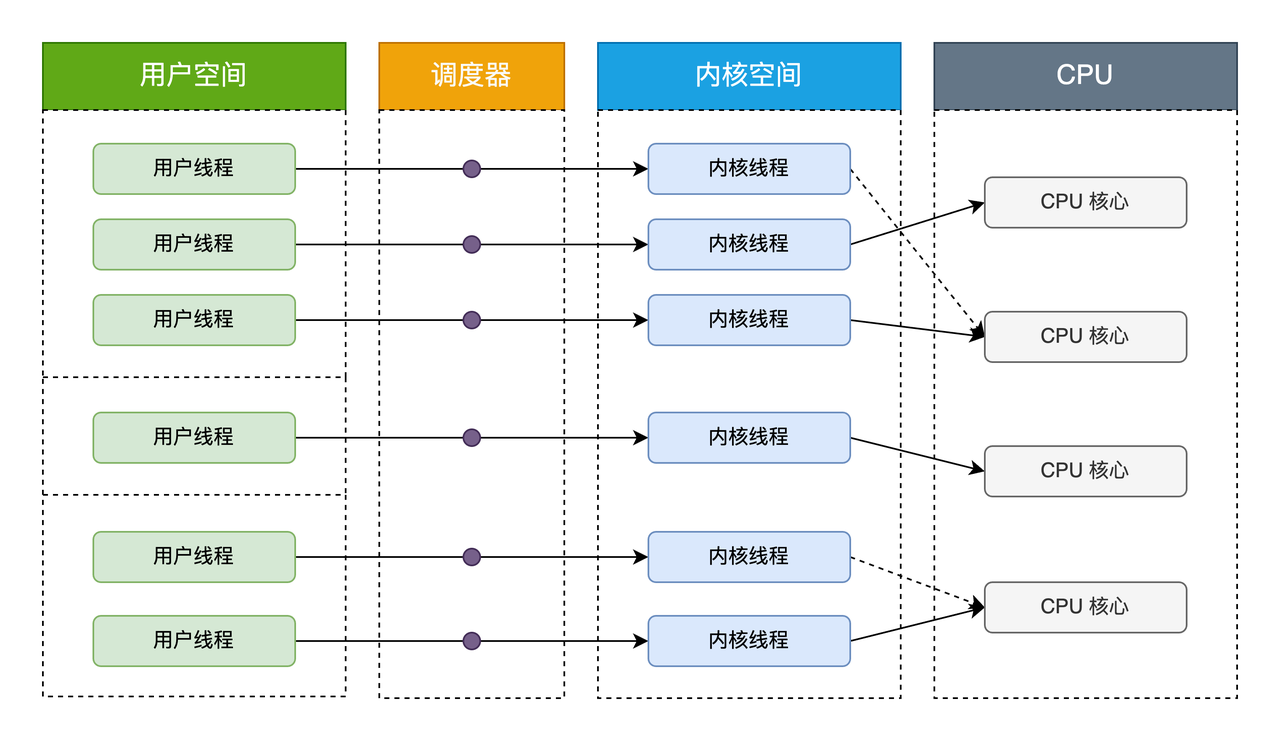
内核级线程模型
内核级线程模型中用户线程与内核线程是一对一关系(1 : 1)。线程的创建、销毁、切换工作都是有内核完成的。应用程序不参与线程的管理工作,只能调用内核级线程编程接口(应用程序创建一个新线程或撤销一个已有线程时,都会进行一个系统调用)。每个用户线程都会被绑定到一个内核线程。用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。
操作系统调度器管理、调度并分派这些线程。运行时库为每个用户级线程请求一个内核级线程。操作系统的内存管理和调度子系统必须要考虑到数量巨大的用户级线程。操作系统为每个线程创建上下文。进程的每个线程在资源可用时都可以被指派到处理器内核。
内核级线程模型有如下优点:
- 在多处理器系统中,内核能够并行执行同一进程内的多个线程
- 如果进程中的一个线程被阻塞,不会阻塞其他线程,是能够切换同一进程内的其他线程继续执行
- 当一个线程阻塞时,内核根据选择可以运行另一个进程的线程,而用户空间实现的线程中,运行时系统始终运行自己进程中的线程
缺点:
- 线程的创建、删除、调度都需要 CPU 参与,成本高
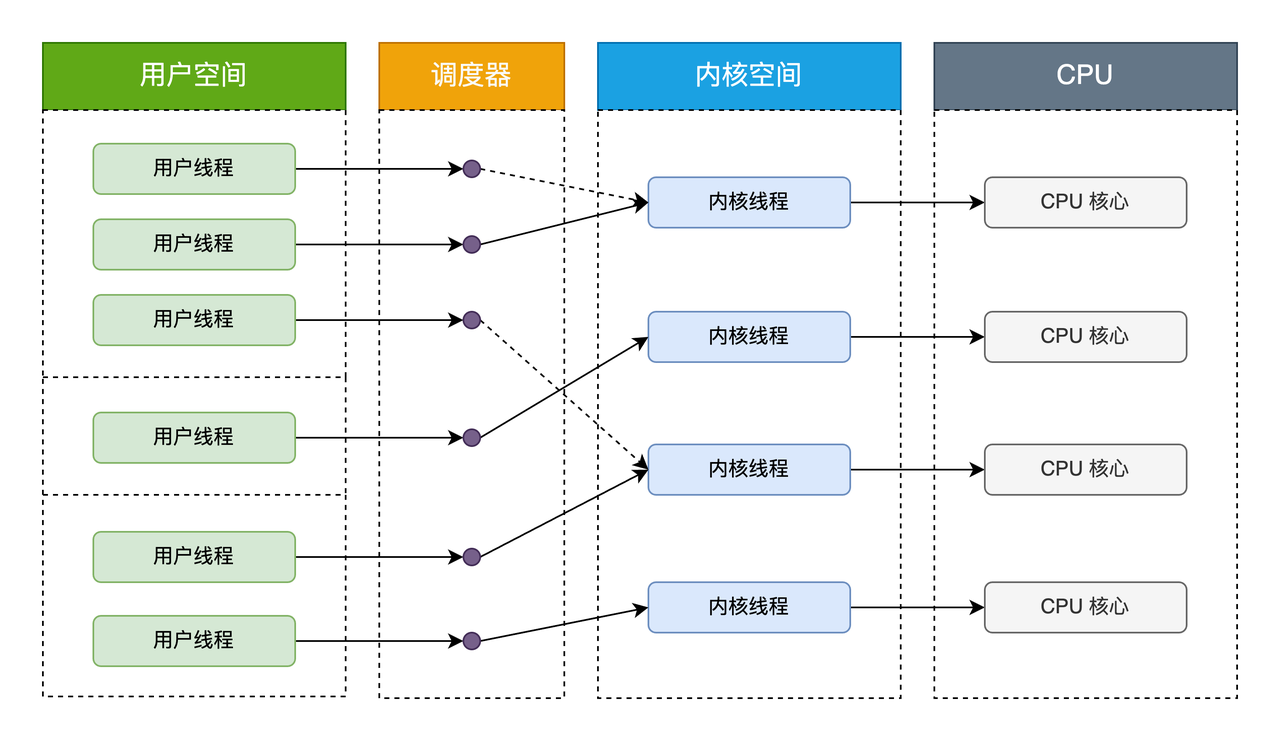
用户级线程模型
用户线程模型中的用户线程与内核线程是多对一关系(N : 1)。线程的创建、销毁以及线程之间的协调、同步等工作都是在用户态完成,具体来说就是由应用程序的线程库控制。内核对用户态的调度是无感知的,内核此时的调度都是基于主线程的。线程的并发处理从宏观来看,任意时刻每个进程只能够有一个线程在运行,且只有一个 CPU 核心会被分配给该进程。
用户级线程有如下优点:
- 创建和销毁线程、线程切换代价等线程管理的代价比内核线程少, 因为保存、恢复线程状态和执行都发生在用户态。
- 线程能够利用的页空间和堆栈空间比内核级线程多。
缺点:
- 线程发生 I/O 调用、页面故障或调用会引起阻塞的系统调用等情况下,由于内核不知道多线程的存在,进而会导致主线程阻塞,从而阻塞用户线程的调度。
- 资源调度按照进程进行,多个处理器下,同一个进程中的线程只能在同一个处理器下分时复用。
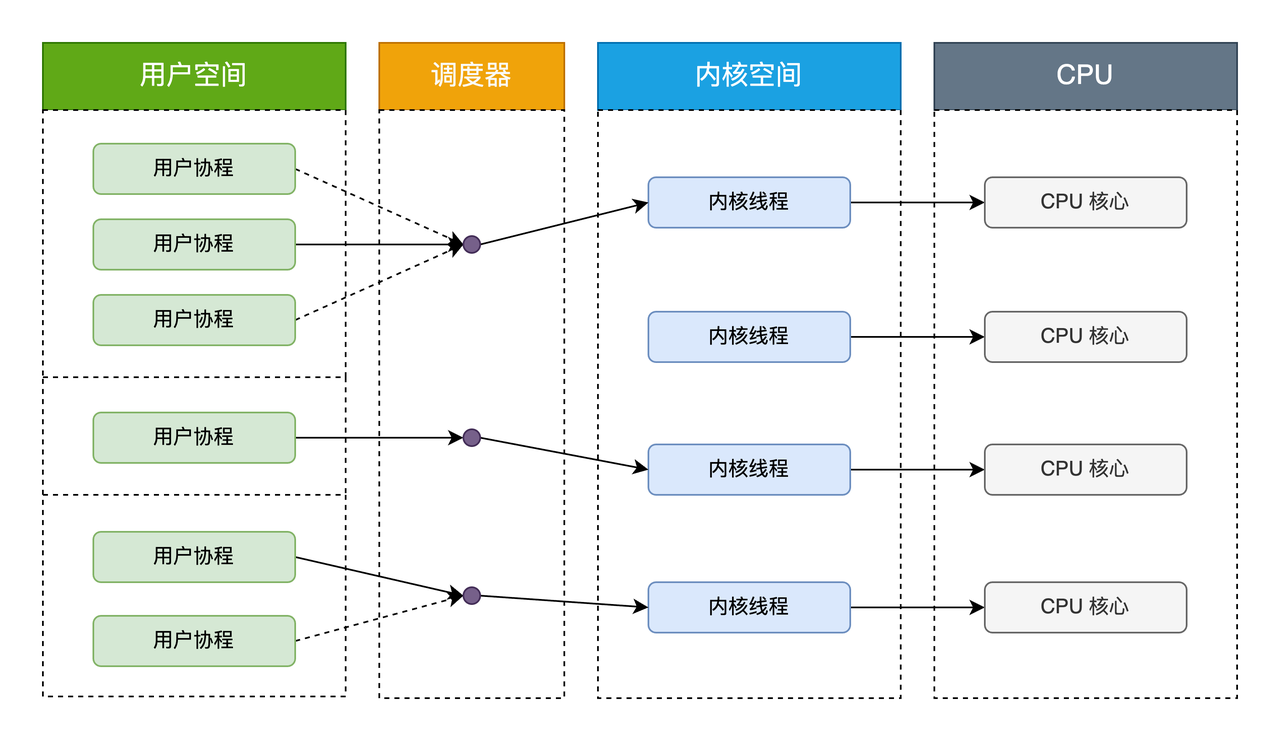
协程模型
协程模型中用户协程与协程调度器绑定,协程调度器在绑定内核线程后执行代码逻辑。协程模型充分吸收上面两种模型的优点,尽量规避缺点。协程创建在用户空间中完成,线程的调度和同步也在应用程序中进行。一个应用程序中的多个协程被绑定到一些(小于或等于用户级线程的数目)内核级线程上。
Plan9 汇编
常用寄存器
SP (Stack Pointer)
SP 寄存器是栈指针寄存器,它总是指向栈顶的当前位置。在函数调用和返回时,以及在局部变量分配时,SP 寄存器会被频繁使用。在 Go 的 Plan 9 汇编中,它通常表示为 SP 或者 RSP(在 64 位 x86 架构上)。
SB (Static Base)
SB 在 Go 的 Plan 9 汇编中是一个伪寄存器,代表静态基址。它用于表示全局地址空间的起点,是全局变量和函数地址的引用基点。SB 不对应任何实际的硬件寄存器。
AX (Accumulator)
AX 寄存器是累加器寄存器,通常用于算术运算、数据传输、I/O 操作和一些特定的指令。在 64 位 x86 架构中,它被扩展为 RAX。在函数调用时,RAX 通常用于存储函数的返回值。
BX (Base)
BX 寄存器是基址寄存器,它可以用于作为地址计算的基点。在 64 位 x86 架构中,BX 被扩展为 RBX。RBX 是少数几个在函数调用时需要被调用者保存(callee-saved)的寄存器之一,这意味着如果一个函数要使用 RBX,它必须在使用前将原来的值压栈,使用后再恢复。
CX (Count)
CX 寄存器是计数寄存器,它经常用于循环和字符串操作指令中表示计数。在 64 位 x86 架构中,它被扩展为 RCX。在某些操作中,如 REP 前缀的字符串操作指令,RCX 寄存器用来计数重复操作的次数。
DX(Data)
DX 寄存器是数据寄存器,用于 I/O 操作和一些算术运算。在 64 位 x86 架构中,它被扩展为 RDX。
PC (Program Counter)
PC 被用来指代当前的指令地址。但是,它的使用方式可能与传统汇编有所不同。在 Go 汇编中,PC 更多地作为一个抽象的概念出现,在不同的架构上会被映射到指定架构的 PC 寄存器。
BP (Base Pointer)
BP寄存器,是表示已给调用栈的起始栈底(栈的方向从大到小,SP表示栈顶),仅部分架构支持,保存栈基地址能较方便地进行栈展开和栈分裂。
GMP 模型
代码分析基于 Go 版本:go1.22.1
概念定义
- G: 调度的基本单位 goroutine 协程。
- M: 操作系统线程,用于执行用户、运行时代码或系统调用。
- P: 表示执行用户 Go 代码所需的资源,如调度程序和内存分配器状态。
每个 goroutine (G) 都在操作系统线程 (M) 上运行,该线程分配给一个逻辑处理器 (P)。
调度模型
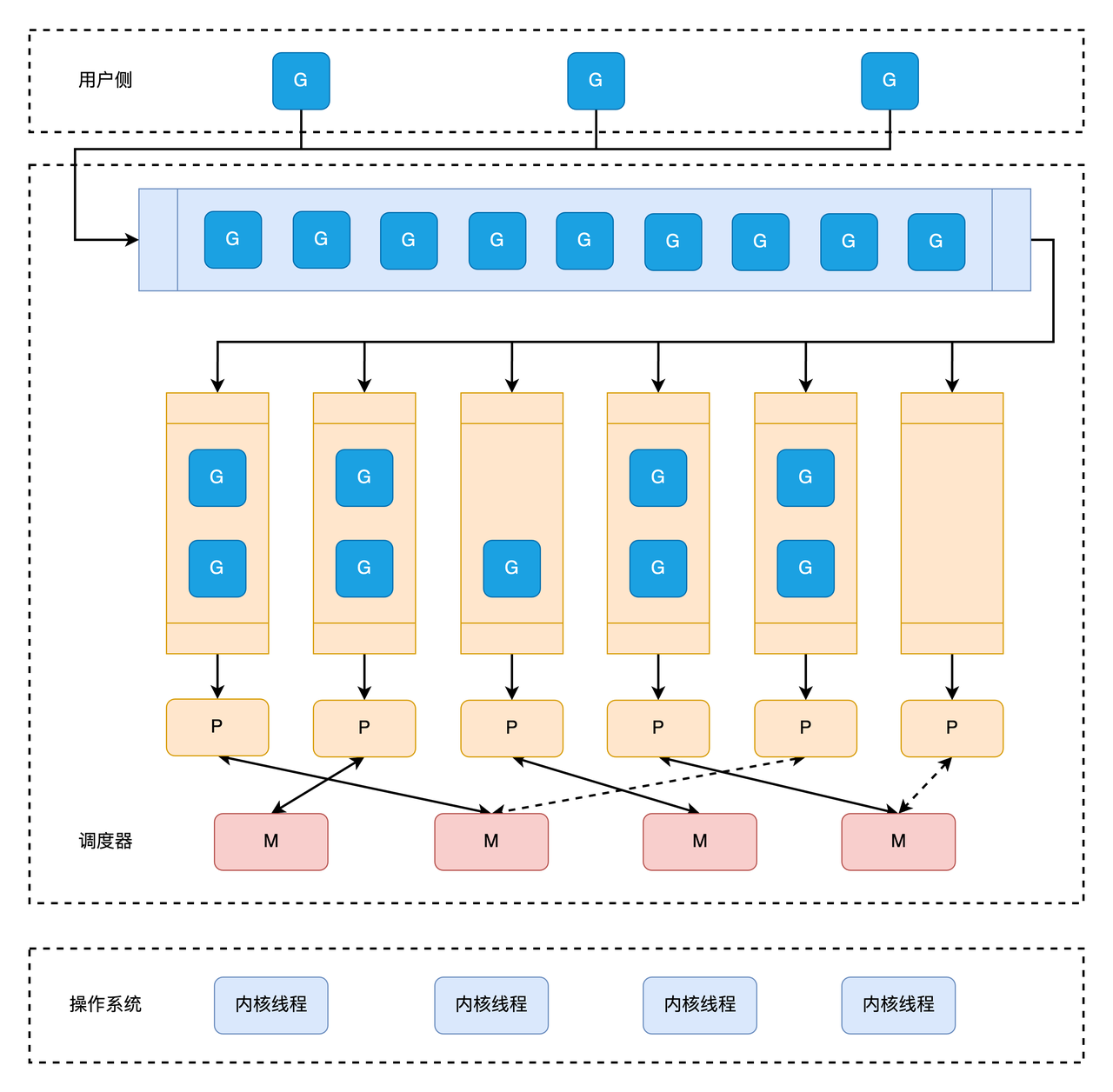
GMP 内部结构
G
// 完整结构参考:https://github.com/golang/go/blob/go1.22.1/src/runtime/runtime2.go
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the //go:systemstack stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// param is a generic pointer parameter field used to pass
// values in particular contexts where other storage for the
// parameter would be difficult to find. It is currently used
// in four ways:
// 1. When a channel operation wakes up a blocked goroutine, it sets param to
// point to the sudog of the completed blocking operation.
// 2. By gcAssistAlloc1 to signal back to its caller that the goroutine completed
// the GC cycle. It is unsafe to do so in any other way, because the goroutine's
// stack may have moved in the meantime.
// 3. By debugCallWrap to pass parameters to a new goroutine because allocating a
// closure in the runtime is forbidden.
// 4. When a panic is recovered and control returns to the respective frame,
// param may point to a savedOpenDeferState.
param unsafe.Pointer
atomicstatus atomic.Uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid uint64
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
...
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
parentGoid uint64 // goid of goroutine that created this goroutine
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
...
selectDone atomic.Uint32 // are we participating in a select and did someone win the race?
...
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}
执行栈管理相关字段
stack字段是一个结构体,它描述了 goroutine 的栈内存的实际边界。这个结构体通常包含两个指针,lo和hi,分别指示栈的底部和顶部的地址。在栈内存范围内,即[stack.lo, stack.hi)区间内的内存是 goroutine 可以安全使用的。stackguard0是一个指针大小的无符号整数,它用于栈增长的检查。在每个函数的序言部分,Go 运行时会检查当前的栈指针是否低于stackguard0。如果是,这意味着栈空间不足,需要进行栈增长操作。通常情况下,stackguard0被设置为stack.lo + StackGuard,StackGuard是一个预定义的边界值,用于在栈空间耗尽前提供一个安全的缓冲区。在预先设定的情况下,stackguard0可以被设置为StackPreempt,以触发 goroutine 的抢占,这是 Go 1.14 引入的协作式抢占机制的一部分。stackguard1是另一个用于栈增长检查的指针大小的无符号整数,它在//go:systemstack(即系统栈)的栈增长序言中比较。对于g0(调度器使用的 goroutine)和gsignal(信号处理使用的 goroutine)的栈,stackguard1通常设置为stack.lo + StackGuard。对于其他 goroutine 的栈,stackguard1通常被设置为~0(所有位都是 1),这样在栈增长检查时将总是失败,导致调用morestackc函数——这是一个运行时函数,如果在非系统栈上调用,会导致程序崩溃。这是一种保护机制,确保 goroutines 在它们自己的栈上运行,而不是在系统栈上。
增长序言(stack growth prologue)在 Go 语言中指的是函数调用时,编译器自动插入的一段代码,用于检查当前 goroutine 的栈是否有足够的空间来执行即将调用的函数。如果检测到栈空间不足,这段代码将触发运行时的栈增长机制,以确保函数有足够的栈空间运行。
在 Go 语言的函数调用中,增长序言是隐式的,开发者通常不需要关心它。但是,它在保证函数调用安全性方面扮演了重要角色,特别是在 Go 语言的并发模型中,每个 goroutine 都有自己的栈,这些栈是动态增长的。
增长序言的工作流程通常如下:
- 在函数调用的开始,检查当前栈指针是否低于
stackguard0(或者在系统栈上的情况下,是否低于stackguard1)。- 如果栈指针高于这个阈值,说明有足够的栈空间,函数调用可以安全进行。
- 如果栈指针低于这个阈值,说明栈空间可能不足,这时会调用运行时的栈增长函数(如
runtime.morestack),为当前 goroutine 分配更多的栈空间。- 栈增长完成后,原来的函数调用将在新的栈空间上继续执行。
这个机制允许 Go 运行时动态地管理每个 goroutine 的栈空间,使得每个 goroutine 可以以较小的初始栈空间开始执行,并且在需要时自动增长,从而支持高效的并发编程模型。
语言特性相关字段
_panic这是指向当前 goroutine 最内层的 panic 的指针。如果一个 goroutine 发生了 panic,这个字段会被用来跟踪 panic 的信息。包括 panic 传入的参数,panic 发生的堆栈位置,panic 是否被 recover 等。_defer这是指向当前 goroutine 最内层的 defer 的指针。Defer 用于保证函数退出时能调用指定的函数。
执行环境和调度相关字段
m: 指向执行当前 goroutine 的 M(OS 线程)的指针。sched: 包含了 goroutine 的调度信息,如栈指针和程序计数器。syscallsp: 如果 goroutine 处于系统调用中,这个字段表示在垃圾回收时应该使用的栈指针。syscallpc: 如果 goroutine 处于系统调用中,这个字段表示在垃圾回收时应该使用的程序计数器。stktopsp: 用于栈回溯时检查的预期栈顶指针。
Goroutine 状态和控制字段
param: 是一个通用的指针参数字段,用于在特定的上下文中传递值。目前主要有以下四种用法:- Channel 操作唤醒阻塞的 goroutine 时,会将 param 指向已完成阻塞操作的
sudog。 - 当一个 goroutine 被要求协助垃圾回收(GC)时,
gcAssistAlloc1函数会使用param字段来向其调用者发出信号,表明该 goroutine 已经完成了它的 GC 周期。使用param字段来进行这种通信是因为在 GC 过程中,goroutine 的栈可能已经移动,直接在栈上操作可能会不安全。 debugCallWrap函数使用param字段来传递参数给一个新的 goroutine。在 Go 运行时中,直接分配闭包可能是被禁止的,因此param字段提供了一种传递参数的方法,而不需要创建闭包。- 当一个 panic 被恢复并且控制返回到相应的栈帧时,
param可能会指向一个savedOpenDeferState结构。这个结构体保存了有关 defer 调用的状态信息,这样在恢复执行时,可以正确地处理 defer 函数。
- Channel 操作唤醒阻塞的 goroutine 时,会将 param 指向已完成阻塞操作的
atomicstatus: goroutine 状态,使用 atomic 方法进行操作。stackLock: 与栈扫描和信号处理相关的锁。goid: 当前 goroutine 的唯一标识符。parentGoid: 创建这个 goroutine 的 goroutine 的 ID。schedlink: 用于调度器的下一个 goroutine 链接。waitsince: goroutine 开始阻塞的时间。waitreason: 如果 goroutine 正在等待,则表示等待的原因。当前共有 37 中原因。gopc: 创建当前 goroutine 的语句的程序计数器ancestors: 创建当前 goroutine 的 goroutine 的信息,仅用于debug.tracebackancestorsstartpc: goroutine 函数的起始程序计数器。
抢占相关字段
preempt: 标记是否应该抢占 goroutine。preemptStop: 如果设置为 true,在抢占时会将 goroutine 的状态设置为_Gpreempted;否则,只是让它退出调度。preemptShrink: 标记是否在安全点缩小栈。
GC 相关字段
inMarkAssist: 是否处于标记辅助状态。在某些情况下,GC 进程可能需要额外的帮助来完成标记工作,尤其是在内存分配速度远远超过垃圾回收速度时。此时,正在进行内存分配的 goroutines 需要"协助"垃圾收集器完成标记工作,这就是所谓的"标记辅助"(Mark Assist)。每个 goroutine 会根据自己分配的内存量来执行一定比例的标记工作,这样可以确保垃圾回收的进度能够跟上内存分配的速度。gcscandone: 表示 goroutine 是否已经扫描了栈。gcAssistBytes: 用于 GC 辅助的计数器,表示这个 goroutine 在分配内存时应该提供多少 GC 辅助。
信号处理相关字段
sig: 信号量sigcode0: 目前用于标记引发SIGFPE和SIGSEGV的具体原因sigcode1: 用于标记引发SIGSEGV信号量的访问地址sigpc: 引发信号量的程序计数器
其他字段
lockedm: 如果 goroutine 被绑定到一个特定的 M,这里会保存 M 的指针。writebuf: 缓冲区,goroutine 输出信息使用,比如堆栈信息等waiting: 指向 goroutine 正在等待的 sudog 结构体链表。paniconfault访问内存地址错误时,panic 替代 crashthrowsplit: 表示这个 goroutine 必须不分裂栈。asyncSafePoint: 如果设置为 true,表示 goroutine 在一个异步安全点停止了。parkingOnChan: 标记当前 goroutine 是否即将进行 chansend 或 chanrecv 操作而休眠,用于指示不安全的栈缩容。nocgocallback: 是否禁用 C 回调(CGO)cgoCtxt: CGO 调用栈跟踪上下文timer: time.Sleep 调用后所缓存的计时器selectDone: 是否成功进入 select 分支
G 的状态
| 状态 | 值 | 含义 |
|---|---|---|
| _Gidle | 0 | Goroutine 被分配,还没有进行初始化。 |
| _Grunnable | 1 | Goroutine 已加入执行队列,尚未执行用户代码,未持有执行栈 |
| _Grunning | 2 | Goroutine 正在执行用户代码,不处于执行队列,持有执行栈。 |
| _Gsyscall | 3 | Goroutine 正在执行系统调用,不处于执行队列,持有执行栈。 |
| _Gwaiting | 4 | Goroutine 处于阻塞等待状态,执行栈根据情况可能被移动保存。等待原因根据 waitReason 可知。 |
| _Gdead | 6 | Goroutine 当前未使用,可能是刚初始化完成或者等待退出 |
| _Gcopystack | 8 | Goroutine 执行栈正在被移动 |
| _Gpreempted | 9 | Goroutine 被抢占,状态类似 _Gwaiting |
Presudo-G
// 完整结构参考:https://github.com/golang/go/blob/go1.22.1/src/runtime/runtime2.go
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
// success indicates whether communication over channel c
// succeeded. It is true if the goroutine was awoken because a
// value was delivered over channel c, and false if awoken
// because c was closed.
success bool
// waiters is a count of semaRoot waiting list other than head of list,
// clamped to a uint16 to fit in unused space.
// Only meaningful at the head of the list.
// (If we wanted to be overly clever, we could store a high 16 bits
// in the second entry in the list.)
waiters uint16
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}
Presudo-G 是处于等待列表的 G 的替身,例如等待往 Channel 发送或从 Channel 接收信息的 Goroutine。之所以要设计替身结构是因为单个 Goroutine 可能同时身处对个等待列表上,因此 Goroutine 和同步对象之间是多对多的关系。
M
// 完整结构参考:https://github.com/golang/go/blob/go1.22.1/src/runtime/runtime2.go
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
_ uint32 // align next field to 8 bytes
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
id int64
...
syscalltick uint32
freelink *m // on sched.freem
trace mTraceState
}
调度相关字段
g0: 持有调度栈的 goroutine,每个 M 都会初始化一个专有的调用 goroutinegsignal: 信号处理专用 goroutinetls: 通过 TLS 实现 m 结构体对象与工作线程之间的绑定curg: 目前正在运行的 goroutine 的指针p: 目前绑定的 P,为空则表示当前没有执行nextp: 当 M 被唤醒时,首先绑定的 Poldp: 执行系统调用前绑定的 Pspinning: 标志 M 是否在自旋等待执行任务alllink: 包含所有 M 的链表的头结点指针schedlink: 下一个 M 的指针lockedg: 和 G 中 locked M 相对应,表示当前 M 绑定的特定的 G
P
// 完整结构参考:https://github.com/golang/go/blob/go1.22.1/src/runtime/runtime2.go
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
pcache pageCache
raceprocctx uintptr
deferpool []*_defer // pool of available defer structs (see panic.go)
deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
//
// Note that while other P's may atomically CAS this to zero,
// only the owner P can CAS it to a valid G.
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
}
调度相关字段
status: P 的当前状态link: 指向 P 链表上的下一个 Pm: 反向指针,指向当前绑定的 Mmcache: P 专用缓存,用于存储小型对象,比如内存分配指标等。pcache: P 持有的可无锁分配的内存页,大小为pageCachePages*pageSize=>8 * unsafe.Sizeof(uint64) * 8192- runqhead: P 本地可执行 Goroutine 队列头指针
- runqtail: P 本地可执行 Goroutine 队列位指针
- runq: P 本地可执行 Goroutine 队列
- runnext: 高优先级可执行 goroutine,插队用
- gFree: 状态为 dead 的 G 链表,在获取 Goroutine 时会优先从这里面获取,可以认为是协程池,避免重复创建对象。最多缓存 64 个,超出会发生减半释放。
P 的状态
| 状态 | 值 | 含义 |
|---|---|---|
| _Pidle | 0 | P 尚未被使用,处于调度器空闲 P 列表中 |
| _Prunning | 1 | P 正在被 M 持有用于执行用户代码 |
| _Psyscall | 2 | P 正在执行系统调用,执行完成后可能会由原有 M 接管,也有可能被分配到其他 M |
| _Pgcstop | 3 | P 暂停运行,此时系统正在进行 GC,直至 GC 结束后才会转变到下一个状态阶段。 |
| _Pdead | 4 | P 不再使用,回收为其分配的资源,一般在缩小 GOMAXPROCS 情况下出现,增大 GOMAXPROCS 后会重新复用(如果有 dead P 的情况下) |
Stack
stack 结构体主要用来记录 goroutine 所使用的栈的信息,包括栈顶和栈底位置。
// Stack describes a Go execution stack.
// The bounds of the stack are exactly [lo, hi),
// with no implicit data structures on either side.
// 用于记录goroutine使用的栈的起始和结束位置
type stack struct{
lo uintptr // 栈顶,指向内存低地址
hi uintptr // 栈底,指向内存高地址
}
Gobuf
gobuf 结构体用于保存 goroutine 的调度信息。
type gobuf struct {
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
//
// ctxt is unusual with respect to GC: it may be a
// heap-allocated funcval, so GC needs to track it, but it
// needs to be set and cleared from assembly, where it's
// difficult to have write barriers. However, ctxt is really a
// saved, live register, and we only ever exchange it between
// the real register and the gobuf. Hence, we treat it as a
// root during stack scanning, which means assembly that saves
// and restores it doesn't need write barriers. It's still
// typed as a pointer so that any other writes from Go get
// write barriers.
sp uintptr // 栈指针,保存了 g 的栈顶地址。在 g 被暂停时,sp 会被设置为当前的栈顶。
pc uintptr // 程序计数器,保存了下一条要执行的指令的地址。当 g 被恢复执行时,会从这个地址开始执行。
g guintptr // 当前 gobuf 对象所属 goroutine 指针
// 上下文指针,用于保存函数调用时的额外上下文信息。
// 在垃圾回收时,它需要特殊处理,因为它可能指向堆上的对象。
// 由于在汇编代码中处理写屏障(write barriers)比较困难,ctxt 被当作根(root)来处理。
// 这意味着它在栈扫描时是活跃的,并且汇编代码中保存和恢复它的操作不需要写屏障。
ctxt unsafe.Pointer
ret uintptr // 保存函数调用的返回值
lr uintptr // 链接寄存器,在那些使用链接寄存器的架构中(如 ARM),保存了函数调用返回的地址
bp uintptr // 基指针,在启用了帧指针的架构中保存当前栈帧的基地址。这对于调试和堆栈展开非常有用
}
调度器
调度器内部结构
// 完整结构参考:https://github.com/golang/go/blob/go1.22.1/src/runtime/runtime2.go
type schedt struct {
lock mutex
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
// sure to call checkdead().
midle muintptr // 空闲的 m
nmidle int32 // 空闲的 m 数量
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // 空闲的 P
npidle atomic.Int32 // 空闲 P 数量
nmspinning atomic.Int32 // See "Worker thread parking/unparking" comment in proc.go.
needspinning atomic.Uint32 // See "Delicate dance" comment in proc.go. Boolean. Must hold sched.lock to set to 1.
// Global runnable queue.
// 全局 _GRunnable G 队列
runq gQueue
runqsize int32
// disable controls selective disabling of the scheduler.
//
// Use schedEnableUser to control this.
//
// disable is protected by sched.lock.
disable struct {
// user disables scheduling of user goroutines.
user bool
runnable gQueue // pending runnable Gs
n int32 // length of runnable
}
// Global cache of dead G's.
// 全局的 GFree 缓存队列,可供 P 获取
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// Central cache of sudog structs.
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs.
deferlock mutex
deferpool *_defer
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
}
调度器生命周期
下面的代码分析以
amd64架构为例
程序首次初始化
g0,m0,工作线程
直接在栈上初始化 g0 栈空间,绑定 m0 和工作线程,并绑定 m0 和 g0。
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
// _cgo_init CGO 相关的初始化可能会更新 Stackguard,暂时忽略
MOVQ $runtime·g0(SB), DI // 保存 runtime.g0 的地址到 DI
LEAQ (-64*1024)(SP), BX // BX 指向线程栈 SP-64*1024+104 处,用于作为 g0 调用栈
MOVQ BX, g_stackguard0(DI) // 修改 runtime.g0.stackguard0 指向 g0 栈底
MOVQ BX, g_stackguard1(DI) // 修改 runtime.g0.stackguard1 指向 g0 栈底
MOVQ BX, (g_stack+stack_lo)(DI) // 修改 runtime.g0.satck.stack_lo 指向 g0 栈底
MOVQ SP, (g_stack+stack_hi)(DI) // 修改 runtime.g0.satck.stack_hi 指向 g0 栈顶
...
LEAQ runtime·m0+m_tls(SB), DI // DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 该函数调用结果取决于不同目标操作系统对 TLS 的管理机制
CALL runtime·settls(SB)
// 获取 FS 段基地址并放入 BX 寄存器,
// 其实就是 m0.tls[1] 的地址,get_tls 的根据系统架构决定
get_tls(BX)
// 把整型常量 0x123 拷贝到 FS 段基地址偏移 -8 的内存位置,
// 也就是m0.tls[0] = 0x123
MOVQ $0x123, g(BX)
// AX=m0.tls[0]
MOVQ runtime·m0+m_tls(SB), AX
// 检查 m0.tls[0] 的值是否是通过线程本地存储存入的 0x123 来验证 tls 功能是否正常
CMPQ AX, $0x123
JEQ 2(PC)
CALL runtime·abort(SB) // 如果线程本地存储不能正常工作,退出程序
ok:
// set the per-goroutine and per-mach "registers"
get_tls(BX)
LEAQ runtime·g0(SB), CX // CX = &g0
MOVQ CX, g(BX) // m0.tls[0] = &g0
LEAQ runtime·m0(SB), AX // AX = &m0
// save m->g0 = g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
调度初始化
// runtime/asm_amd64.s
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
ok:
...
MOVL 24(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 32(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB) // 读取程序参数
CALL runtime·osinit(SB) // 针对操作系统初始化
CALL runtime·schedinit(SB) // 调度初始化
...
主调度初始化函数,通过信号量 STW,随后进行所有的必要的初始化操作
// runtime/proc.go
func schedinit() {
// 初始化调度器的各种锁,防止调度过程中的并发修改
lockInit(&sched.lock, lockRankSched)
...
lockInit(&memstats.heapStats.noPLock, lockRankLeafRank)
gp := getg() // gp = g0
...
// 默认设置最多启动 10000 个操作系统线程,也是最多 10000 个 M
// 决定处于执行状态的 M 的数量取决于 GOMAXPROCS 也就是 P 的数量
sched.maxmcount = 10000
// 包括初始化堆栈内存池,根据 CPU 架构确定可用扩展指令集等
...
mcommoninit(gp.m, -1) // 初始化 m0, gp.m = m0
...
// 初始化 Ps
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
...
}
mcommoninit() 函数会对 m0 进行初始化
// Pre-allocated ID may be passed as 'id', or omitted by passing -1.
func mcommoninit(mp *m, id int64) {
gp := getg() // gp = g0
// g0 stack won't make sense for user (and is not necessary unwindable).
if gp != gp.m.g0 {
callers(1, mp.createstack[:])
}
lock(&sched.lock)
// 获取线程 id
// 并检查已创建数量是否已经超过最大值
if id >= 0 {
mp.id = id
} else {
mp.id = mReserveID()
}
// 初始化随机数生成相关状态
mrandinit(mp)
// 初始化信号处理 goroutine
mpreinit(mp)
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + stackGuard
}
// 把新创建的 m 加入到 allm 链表上
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
// NumCgoCall() and others iterate over allm w/o schedlock,
// so we need to publish it safely.
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// Allocate memory to hold a cgo traceback if the cgo call crashes.
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" {
mp.cgoCallers = new(cgoCallers)
}
}
procresize() 函数对 P 进行初始化
func procresize(nprocs int32) *p {
// 检查锁和 STW 状态
assertLockHeld(&sched.lock)
assertWorldStopped()
...
// 首次初始化 gomaxprocs = 0
old := gomaxprocs
...
if nprocs > int32(len(allp)) {
lock(&allpLock)
// 非初始化缩容操作
if nprocs <= int32(cap(allp)) {
allp = allp[:nprocs]
} else {
// 初始化 allp Slice
nallp := make([]*p, nprocs)
// 初始化时 allp 为空,会跳过 copy 操作
// 运行时扩容会将 cap 个 P 复制到新创建的 allp 中避免丢失
copy(nallp, allp[:cap(allp)])
allp = nallp
}
...
unlock(&allpLock)
}
// 初始化新创建的 Ps
for i := old; i < nprocs; i++ {
pp := allp[i]
if pp == nil {
pp = new(p)
}
// 设置 P 的 id, 状态,内存缓存等
// 此时 P 的状态为 _Pgcstop
pp.init(i)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
gp := getg() // gp = g0
if gp.m.p != 0 && gp.m.p.ptr().id < nprocs {
// 执行 Resize 操作的 P 不在释放范围
// 则使用当前 P 继续下列操作
gp.m.p.ptr().status = _Prunning
gp.m.p.ptr().mcache.prepareForSweep()
} else {
// 执行 Resize 操作的 P 在释放范围
// 则释放当前的 P,从刚初始化好的 allp 切片中获取 0 号位的 P 继续下列操作
// 由于写屏障的限制,释放 P 的操作也要由新 P 代劳
if gp.m.p != 0 {
// 一些 Trace 操作
...
gp.m.p.ptr().m = 0
}
gp.m.p = 0
pp := allp[0]
pp.m = 0
pp.status = _Pidle
acquirep(pp) // 新 P 绑定原有 P 的 M,通过 getg() 获取 g.m
// 一些 Trace 操作
...
}
// 释放未使用的 P 的资源
// 初始化时因为 old = 0 所以会跳过
for i := nprocs; i < old; i++ {
pp := allp[i]
pp.destroy()
// can't free P itself because it can be referenced by an M in syscall
}
...
var runnablePs *p
// 下面这个for 循环把所有空闲的p放入空闲链表
for i := nprocs - 1; i >= 0; i-- {
pp := allp[i]
// 跳过当前正在执行 resize 操作的 P
if gp.m.p.ptr() == pp {
continue
}
pp.status = _Pidle
if runqempty(pp) {
pidleput(pp, now)
} else {
// 从 schedt.midle 获取空闲的 m,可能为空
pp.m.set(mget())
pp.link.set(runnablePs)
runnablePs = pp
}
}
...
return runnablePs
}
至此,完成了 g0, m0 和 m0, p 的绑定,程序可以开始进行调度。
创建入口 Goroutine
// runtime/asm_amd64.s
// 全局变量 runtime·mainPC
// 后面 runtime·rt0_go 会使用这个入口点初始化一个 goroutine 启动程序
DATA runtime·mainPC+0(SB)/8,$runtime·main<ABIInternal>(SB)
GLOBL runtime·mainPC(SB),RODATA,$8
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
ok:
...
// 创建一个新的 goroutine 加入队列以启动程序
// 程序入口点,全局变量指向 runtime·main 函数
MOVQ $runtime·mainPC(SB), AX
PUSHQ AX
CALL runtime·newproc(SB) // 创建新 goroutine 加入执行队列
POPQ AX
初始化工作都完成后,将 mainPC 指向的 runtime.main 函数传入 runtime.newproc,创建了一个新的 goroutine。
// Create a new g running fn.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
func newproc(fn *funcval) {
// 初始化时,gp = runtime.g0
// 否则为调用方 g
gp := getg()
// getcallerpc() 返回一个地址,
// 也就是调用 newproc 时调用语句所在的地址
// 用于完成 newproc 调用后继续执行原有逻辑
pc := getcallerpc()
// systemstack() 函数的作用是切换到 g0 栈执行作为参数的函数
// 如果本身为 m.g0 或 m.gsignal 调用,则无需进行栈切换
systemstack(func() {
// newproc1 会初始化对应调用的 g, 绑定 m, p 等
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr()
// runqput 将 g 入队调度
// 如果开启了 race detector, 会根据随机数将 next 参数置为 false
// next 参数为 true 替换当前 P 的 runnext
// P 原有 runnext 不为空则放入 P 本地队列
// P 本地队列满则放入全局队列
runqput(pp, newg, true)
if mainStarted {
wakep()
}
})
}
// Create a new g in state _Grunnable, starting at fn. callerpc is the
// address of the go statement that created this. The caller is responsible
// for adding the new g to the scheduler.
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
if fn == nil {
fatal("go of nil func value")
}
// 获取当前 getg().m
// 会加锁避免争抢
mp := acquirem() // disable preemption because we hold M and P in local vars.
pp := mp.p.ptr()
// 1. 从本地队列 p.gFree 获取空闲的 g
// 2. 从全局队列按 schedt.gFree.stack 先,schedt.gFree.nostack 后的顺序获取空闲的 g
// 3. 队列为空,初始化新的 g
newg := gfget(pp)
if newg == nil {
newg = malg(stackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack.
}
// 检查 g 栈分配
if newg.stack.hi == 0 {
throw("newproc1: newg missing stack")
}
// 检查 g 的状态
if readgstatus(newg) != _Gdead {
throw("newproc1: new g is not Gdead")
}
...
// 清空 newg.sched
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched))
// 保存栈顶指针
newg.sched.sp = sp
newg.stktopsp = sp
// newg.sched.pc表示当newg被调度起来运行时从这个地址开始执行指令
// 当前把pc设置成了 goexit 这个函数地址 + 1(sys.PCQuantum等于1)的位置
newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
newg.sched.g = guintptr(unsafe.Pointer(newg))
// 调整 gobuf(newg.sched) 和 newg 的栈空间
gostartcallfn(&newg.sched, fn)
newg.parentGoid = callergp.goid
newg.gopc = callerpc
newg.ancestors = saveAncestors(callergp)
newg.startpc = fn.fn
...
// 切换为 _Grunnable 状态
casgstatus(newg, _Gdead, _Grunnable)
...
releasem(mp)
return newg
}
// adjust Gobuf as if it executed a call to fn
// and then stopped before the first instruction in fn.
func gostartcallfn(gobuf *gobuf, fv *funcval) {
var fn unsafe.Pointer
if fv != nil {
fn = unsafe.Pointer(fv.fn)
} else {
fn = unsafe.Pointer(abi.FuncPCABIInternal(nilfunc))
}
gostartcall(gobuf, fn, unsafe.Pointer(fv))
}
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then stopped before the first instruction in fn.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
// 从 buf.sp(栈指针)中减去指针大小(goarch.PtrSize)
// 为即将“伪造”的函数调用腾出空间。
// 这类似在 x86 架构上的 "CALL" 指令行为,它会将返回地址压栈。
sp -= goarch.PtrSize
// 将 buf.pc(程序计数器,即将要返回的地址)保存到新的栈顶位置。
// 这模拟了函数调用时的行为——当前的 pc 值是调用函数后应该返回到的点。
// 使得 fn 执行完后返回到 goexit 继续执行,从而完成清理工作
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
// 重新设置 newg 栈顶
buf.sp = sp
// 将真正需要执行的函数赋值给 newg.sched.pc
// 当 goroutine 恢复执行时,它将从这个地址开始执行。
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
启动 m0
// runtime/asm_amd64.s
// m0 启动函数,大部分架构都指向 runtime·mstart0
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME|NOFRAME,$0
CALL runtime·mstart0(SB)
RET // not reached
TEXT runtime·rt0_go(SB),NOSPLIT|NOFRAME|TOPFRAME,$0
...
ok:
...
// start this M
CALL runtime·mstart(SB) // 启动 m0
CALL runtime·abort(SB) // mstart should never return
RET
... // 针对不符合要求的处理器架构的操作,报错退出
// mstart0 is the Go entry-point for new Ms.
// This must not split the stack because we may not even have stack
// bounds set up yet.
//
// May run during STW (because it doesn't have a P yet), so write
// barriers are not allowed.
//
//go:nosplit
//go:nowritebarrierrec
func mstart0() {
gp := getg()
osStack := gp.stack.lo == 0
if osStack {
// Initialize stack bounds from system stack.
// Cgo may have left stack size in stack.hi.
// minit may update the stack bounds.
//
// Note: these bounds may not be very accurate.
// We set hi to &size, but there are things above
// it. The 1024 is supposed to compensate this,
// but is somewhat arbitrary.
size := gp.stack.hi
if size == 0 {
size = 16384 * sys.StackGuardMultiplier
}
gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size)))
gp.stack.lo = gp.stack.hi - size + 1024
}
// Initialize stack guard so that we can start calling regular
// Go code.
gp.stackguard0 = gp.stack.lo + stackGuard
// This is the g0, so we can also call go:systemstack
// functions, which check stackguard1.
gp.stackguard1 = gp.stackguard0
mstart1()
// Exit this thread.
if mStackIsSystemAllocated() {
// Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate
// the stack, but put it in gp.stack before mstart,
// so the logic above hasn't set osStack yet.
osStack = true
}
mexit(osStack)
}
// The go:noinline is to guarantee the getcallerpc/getcallersp below are safe,
// so that we can set up g0.sched to return to the call of mstart1 above.
//
//go:noinline
func mstart1() {
gp := getg()
// 限制 mstart 必须在 m.g0 上调用
if gp != gp.m.g0 {
throw("bad runtime·mstart")
}
// Set up m.g0.sched as a label returning to just
// after the mstart1 call in mstart0 above, for use by goexit0 and mcall.
// We're never coming back to mstart1 after we call schedule,
// so other calls can reuse the current frame.
// And goexit0 does a gogo that needs to return from mstart1
// and let mstart0 exit the thread.
gp.sched.g = guintptr(unsafe.Pointer(gp))
// 保存再次运行时的指令地址,即返回后会执行线程退出操作
gp.sched.pc = getcallerpc()
// 保存再次运行时的栈顶
gp.sched.sp = getcallersp()
// 部分 CPU 架构要进行特殊的初始化
asminit()
// 信号相关初始化
minit()
// Install signal handlers; after minit so that minit can
// prepare the thread to be able to handle the signals.
// 针对 M0 的信号初始化
if gp.m == &m0 {
mstartm0()
}
// 执行启动函数
// 首次初始化 g0.m.mstart = nil
if fn := gp.m.mstartfn; fn != nil {
fn()
}
// m0已经绑定了 allp[0],不是 m0 的话还没有 p,所以需要获取一个 p
if gp.m != &m0 {
acquirep(gp.m.nextp.ptr())
gp.m.nextp = 0
}
// 开始调度
schedule()
}
执行调度
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
// 初始化时是 m0.g0, 其他为 m.g0
mp := getg().m
...
top:
...
gp, inheritTime, tryWakeP := findRunnable() // 阻塞获取 Runnable goroutine
...
execute(gp, inheritTime) // 执行获取到的 goroutine
}
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
// tryWakeP indicates that the returned goroutine is not normal (GC worker, trace
// reader) so the caller should try to wake a P.
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
mp := getg().m
...
// Try to schedule a GC worker.
// GC 辅助任务
if gcBlackenEnabled != 0 {
gp, tnow := gcController.findRunnableGCWorker(pp, now)
if gp != nil {
return gp, false, true
}
now = tnow
}
// 为了保证调度的公平性,每进行61次调度就需要优先从全局运行队列中获取goroutine,
// 因为如果只调度本地队列中的g,那么全局运行队列中的goroutine将得不到运行
if pp.schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp := globrunqget(pp, 1)
unlock(&sched.lock)
if gp != nil {
return gp, false, false
}
}
}
// Schedules gp to run on the current M.
// If inheritTime is true, gp inherits the remaining time in the
// current time slice. Otherwise, it starts a new time slice.
// Never returns.
//
// Write barriers are allowed because this is called immediately after
// acquiring a P in several places.
//
//go:yeswritebarrierrec
func execute(gp *g, inheritTime bool) {
// 获取当前 m
// 初始化时是 m0
mp := getg().m
...
// 切换 curg 为待调度的 newg
mp.curg = gp
gp.m = mp
// 切换状态
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + stackGuard
if !inheritTime {
mp.p.ptr().schedtick++
}
...
// 执行
gogo(&gp.sched)
}
// func gogo(buf *gobuf)
// restore state from Gobuf; longjmp
TEXT runtime·gogo(SB), NOSPLIT, $0-8
MOVQ buf+0(FP), BX // gobuf, BX = buf
MOVQ gobuf_g(BX), DX // DX = gp.sched.g
MOVQ 0(DX), CX // make sure g != nil
JMP gogo<>(SB)
TEXT gogo<>(SB), NOSPLIT, $0
get_tls(CX)
// 把要运行的 g 的指针放入线程本地存储,这样后面的代码就可以通过线程本地存储
// 获取到当前正在执行的 goroutine 的 g 结构体对象,从而找到与之关联的 m 和 p
MOVQ DX, g(CX)
MOVQ DX, R14 // go 常用 R14 寄存器保存当前执行的 g
MOVQ gobuf_sp(BX), SP // restore SP, 恢复 g 执行栈
MOVQ gobuf_ret(BX), AX // AX = &buf.ret
MOVQ gobuf_ctxt(BX), DX // DX = &buf.ctxt
MOVQ gobuf_bp(BX), BP // BP = &buf.bp
// 清空 sched 的值,因为我们已把相关值放入CPU对应的寄存器了,不再需要,这样做可以少gc的工作量
MOVQ $0, gobuf_sp(BX) // clear to help garbage collector
MOVQ $0, gobuf_ret(BX)
MOVQ $0, gobuf_ctxt(BX)
MOVQ $0, gobuf_bp(BX)
MOVQ gobuf_pc(BX), BX // BX = &buf.pc
JMP BX // 跳转开始执行函数
执行 main
//go:linkname main_main main.main
func main_main()
// The main goroutine.
func main() {
mp := getg().m
// Max stack size is 1 GB on 64-bit, 250 MB on 32-bit.
// Using decimal instead of binary GB and MB because
// they look nicer in the stack overflow failure message.
// 64 位系统上每个 goroutine 的栈最大可达 1G
// 否则为 250MB
if goarch.PtrSize == 8 {
maxstacksize = 1000000000
} else {
maxstacksize = 250000000
}
// An upper limit for max stack size. Used to avoid random crashes
// after calling SetMaxStack and trying to allocate a stack that is too big,
// since stackalloc works with 32-bit sizes.
maxstackceiling = 2 * maxstacksize
// Allow newproc to start new Ms.
// 标志主 Goroutine 已启动
mainStarted = true
...
//调用main.main函数
fn := main_main // make an indirect call, as the linker doesn't know the address of the main package when laying down the runtime
fn()
...
exit(0)
// 保护性代码,exit 出错也能强制进程退出
for {
var x *int32
*x = 0
}
}
Goroutine 调度
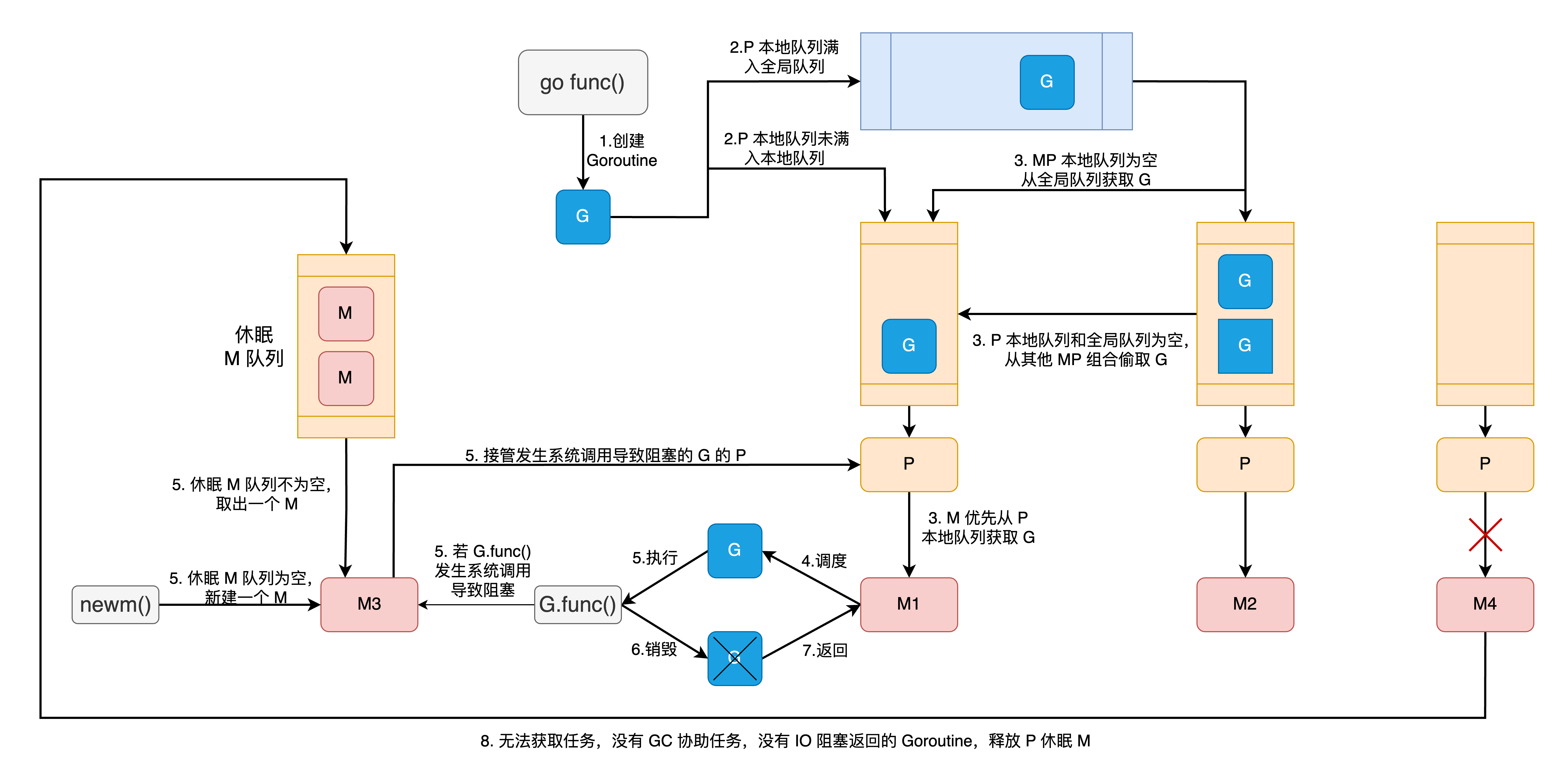
调度循环: schedule() -> execute() -> gogo() -> g.func() -> goexit() -> goexit1() -> goexit0() -> schedule()
创建 Goroutine
从 Go 编译器代码可以更明确得知 go 关键字所执行的操作就是执行 runtime.newproc。
// src/cmd/compile/internal/ssagen/ssa.go
func InitConfig() {
...
ir.Syms.Newproc = typecheck.LookupRuntimeFunc("newproc")
...
}
// Calls the function n using the specified call type.
// Returns the address of the return value (or nil if none).
func (s *state) call(n *ir.CallExpr, k callKind, returnResultAddr bool, deferExtra ir.Expr) *ssa.Value {
...
// call target
switch {
...
case k == callGo:
aux := ssa.StaticAuxCall(ir.Syms.Newproc, s.f.ABIDefault.ABIAnalyzeTypes(ACArgs, ACResults))
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux) // TODO paramResultInfo for Newproc
...
}
}
调用 runtime.newproc,会先调用 runtime.newproc1 获取或创建 goroutine ,分以下几种情况:
acquirem()获取的 MP 组合的 P 本地gFree为空,从schedt的gFree缓存中按sched.gFree.stack先,sched.gFree.noStack后的顺序最多获取 32 个可复用的 goroutine 对象。acquirem()获取的 MP 组合的 P 本地gFree不为空,直接从 P 本地gFree中获取可复用的 goroutine 对象。- 没有可复用的 goroutine 对象,则通过
malg()函数,创建新的 goroutine。
随后 runtime.newproc1 还会对获取到的 goroutine 对象进行初始化,包括修改状态和变量,初始化 g.sched 结构用于调度等。
最后 runtime.newproc 会调用 runtime.runqput 函数将初始化好的 goroutine 进行入队,先把新创建的 goroutine 放入 P 的 runnext,如果有旧的 runnext,则尝试将旧的 runnext 放入 P 的本地队列,本地队列满则将旧的 runnext 放入全局队列。因为 runtime.newproc 调用 runtime.runqput 时,next 参数传 true。
其他的操作和创建入口 Goroutine 类似,只是执行的函数换成了实际所要执行的函数。前面没有提到的一个小细节是自 go1.18 后,编译器会将 go/defer 闭包调用标准化成普通函数调用方式。runtime.newproc1 原本需要将函数参数复制到调用栈上的操作被简化。
// normalizeGoDeferCall normalizes call into a normal function call
// with no arguments and no results, suitable for use in an OGO/ODEFER
// statement.
//
// For example, it normalizes:
//
// f(x, y)
//
// into:
//
// x1, y1 := x, y // added to init
// func() { f(x1, y1) }() // result
func normalizeGoDeferCall(pos src.XPos, op ir.Op, call ir.Node, init *ir.Nodes) *ir.CallExpr
举个例子:
// main.go
package main
import "time"
func main() {
aa, bb, cc := 1,2,3
go func(a, b, c int) {
println(a, b, c)
}(aa,bb,cc)
}
// GOOS=linux GOARCH=amd64 go build -gcflags=-S main.go
main.main STEXT size=89 args=0x0 locals=0x18 funcid=0x0 align=0x0
0x0000 00000 (main.go:4) TEXT main.main(SB), ABIInternal, $24-0
...
// 拷贝对象地址
0x000e 00014 (main.go:6) LEAQ type:noalg.struct { F uintptr; X0 func(int, int, int); X1 int; X2 int; X3 int }(SB), AX
0x0015 00021 (main.go:6) PCDATA $1, $0
// 堆上分配内存初始化对象
0x0015 00021 (main.go:6) CALL runtime.newobject(SB)
// 复制 gowarp1 函数地址到 CX 赋值 struct.F
0x001a 00026 (main.go:6) LEAQ main.main.gowrap1(SB), CX
0x0021 00033 (main.go:6) MOVQ CX, (AX)
// 复制 func1 函数地址到 CX, 赋值 struct.X0
0x0024 00036 (main.go:6) LEAQ main.main.func1·f(SB), CX
0x002b 00043 (main.go:6) MOVQ CX, 8(AX)
// 分别将调用参数赋值 struct.X1, struct.X2, struct.X3
0x002f 00047 (main.go:6) MOVQ $1, 16(AX)
0x0037 00055 (main.go:6) MOVQ $2, 24(AX)
0x003f 00063 (main.go:6) MOVQ $3, 32(AX)
// 使用 struct 调用 runtime.newproc 函数
0x0047 00071 (main.go:6) CALL runtime.newproc(SB)
...
main.main.gowrap1 STEXT size=141 args=0x0 locals=0x28 funcid=0x16 align=0x0
...
main.main.func1 STEXT size=135 args=0x18 locals=0x10 funcid=0x0 align=0x0
...
type:noalg.struct { F uintptr; X0 func(int, int, int); X1 int; X2 int; X3 int } SRODATA dupok size=200
...
执行调度
执行调度和首次调度 main Goroutine 类似,
Goroutine 退出
前面在描述创建入口 goroutine 的逻辑有说过,将 goroutine 栈顶返回地址指向了 goexit 函数,goroutine 在完成函数执行后就会跳转执行 goexit 函数
// The top-most function running on a goroutine
// returns to goexit+PCQuantum.
TEXT runtime·goexit(SB),NOSPLIT|TOPFRAME|NOFRAME,$0-0
BYTE $0x90 // NOP
CALL runtime·goexit1(SB) // does not return
// traceback from goexit1 must hit code range of goexit
BYTE $0x90 // NOP
func goexit1() {
...
mcall(goexit0)
}
// goexit continuation on g0.
func goexit0(gp *g) {
// 针对已执行完成的 goroutine 进行一些清理和销毁工作
gdestroy(gp)
// 再次调度,寻找可供执行的 goroutine
schedule()
}
// func mcall(fn func(*g))
// Switch to m->g0's stack, call fn(g).
// Fn must never return. It should gogo(&g->sched)
// to keep running g.
// 主要作用是切换到 m.g0 执行 goexit0
TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8
// 从 AX 取出参数的值放入DI寄存器,它是 funcval 对象的指针。
// 此场景中 fn 是 goexit0 函数的地址
MOVQ AX, DX // DX = fn
// Save state in g->sched. The caller's SP and PC are restored by gogo to
// resume execution in the caller's frame (implicit return). The caller's BP
// is also restored to support frame pointer unwinding.
MOVQ SP, BX // hide (SP) reads from vet
MOVQ 8(BX), BX // caller's PC
MOVQ BX, (g_sched+gobuf_pc)(R14)
LEAQ fn+0(FP), BX // caller's SP
MOVQ BX, (g_sched+gobuf_sp)(R14)
// Get the caller's frame pointer by dereferencing BP. Storing BP as it is
// can cause a frame pointer cycle, see CL 476235.
MOVQ (BP), BX // caller's BP
MOVQ BX, (g_sched+gobuf_bp)(R14)
// switch to m->g0 & its stack, call fn
MOVQ g_m(R14), BX
MOVQ m_g0(BX), SI // SI = g.m.g0
CMPQ SI, R14 // if g == m->g0 call badmcall
JNE goodm
JMP runtime·badmcall(SB)
goodm:
MOVQ R14, AX // AX (and arg 0) = g
MOVQ SI, R14 // g = g.m.g0
get_tls(CX) // Set G in TLS
MOVQ R14, g(CX)
MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp
PUSHQ AX // open up space for fn's arg spill slot
MOVQ 0(DX), R12
CALL R12 // fn(g)
POPQ AX
JMP runtime·badmcall2(SB)
RET

