Go 编译器浅析
编译原理基础知识
词法分析
词法分析(lexical analysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
词法分析的第一阶段即扫描器,通常基于有限状态自动机。扫描器能够识别其所能处理的标记中可能包含的所有字符序列(单个这样的字符序列即前面所说的“语素”)。例如“整数”标记可以包含所有数字字符序列。很多情况下,根据第一个非空白字符便可以推导出该标记的类型,于是便可逐个处理之后的字符,直到出现不属于该类型标记字符集中的字符(即最长一致原则)。
词法分析器的工作是低级别的分析:将字符或者字符序列转化成记号。在谈论词法分析时,使用术语“词法记号”(简称记号)、“模式”和“词法单元”表示特定的含义。
有限状态自动机
有限状态自动机 (FSM finite state machine 或者FSA finite state automaton) 是为研究有限内存的计算过程和某些语言类而抽象出的一种计算模型。有限状态自动机拥有有限数量的状态,每个状态可以迁移到零个或多个状态,输入字串决定执行哪个状态的迁移。有限状态自动机可以表示为一个有向图。有限状态自动机是自动机理论的研究对象。
语法分析
在计算机科学和语言学中,语法分析(英:Syntactic analysis,也叫Parsing)是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。语法分析器(Parser)通常是作为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。
语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的“单词”,并将单词流作为其输入。实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成。
上下文无关文法
上下文无关文法(Context-Free Grammar,CFG)是编译原理中用来描述编程语言的语法结构的一种形式化方法。它是一种生成式文法,用来定义由一组规则组成的语言,这些规则决定了一个字符串是否属于该语言。
上下文无关文法由四个部分组成:
- 终结符集合(Terminal symbols):这些是语言中实际出现的字符或词汇,如编程语言中的关键字、操作符、标识符等。
- 非终结符集合(Non-terminal symbols):这些符号代表终结符的各种组合和模式,它们用来构建更高层次的结构,如表达式、语句等。
- 产生式集合(Production rules):这些规则定义了非终结符和终结符如何组合成合法的字符串。每个产生式包含一个非终结符(产生式的左侧)和一个终结符和/或非终结符的序列(产生式的右侧)。产生式表达了如何从一个非终结符生成一个字符串。
- 开始符号(Start symbol):这是非终结符集合中的一个特殊符号,表示整个语言的起始点。
上下文无关文法的一个关键特性是其产生式的应用不依赖于字符串中的上下文。这意味着,无论在字符串的哪个位置,只要找到匹配的非终结符,就可以应用相应的产生式进行替换。上下文无关文法足够强大,可以描述大多数编程语言的语法。
在编译器设计中,上下文无关文法通常用于构建语法分析器,该分析器能够根据语言的语法规则解析源代码,并构建出一个抽象语法树(Abstract Syntax Tree,AST),这个树结构反映了源代码的层次结构,便于后续的语义分析和代码生成。
解析方法
自顶向下解析
自顶向下解析是从语法分析树的根节点开始,逐步向下扩展叶节点的过程。它使用预测分析法,根据当前输入和语法规则来预测下一个可能的产生式。自顶向下解析的典型方法是递归下降分析和LL(1)分析。递归下降分析是一种简单直观的方法,它为每个非终结符编写一个递归函数,函数内部根据输入和语法规则选择合适的产生式进行递归调用。LL(1)分析是一种更为高效的自顶向下解析方法,它使用一个预测分析表来指导分析过程,能够在不回溯的情况下进行分析。
自底向上解析
自底向上解析是从语法分析树的叶节点开始,逐步向上归约到根节点的过程。它使用移进-归约法,根据当前输入和语法规则来决定是将输入移进分析栈还是进行归约操作。自底向上解析的典型方法是LR分析,包括LR(0)、SLR(1)、LALR(1)和LR(1)等变种。LR分析使用一个分析表和一个分析栈来控制分析过程,能够处理大多数上下文无关语法。
自顶向下解析和自底向上解析各有优缺点。自顶向下解析比较直观,容易理解和实现,但是它不能处理左递归语法且效率较低。自底向上解析能够处理更为复杂的语法,效率更高,但是实现起来更为复杂。
向前查看
在语法分析中除了 LL 和 LR 这两种不同类型的语法分析方法之外,还存在另一个非常重要的概念,就是向前查看(Lookahead),在不同生产规则发生冲突时,当前解析器需要通过预读一些 Token 判断当前应该用什么生产规则对输入流进行展开或者归约(19),例如在 LALR(1) 文法中,需要预读一个 Token 保证出现冲突的生产规则能够被正确处理。
中间表示 / 中间代码
大多数编译器会首先将源程序翻译成某种中间表示形式,然后再将其转换成机器码。中间表示是原始源代码的机器和语言独立版本。尽管两次转换代码引入了另一个步骤,但使用中间表示在提高抽象性、编译器前后端解耦、支持多种架构编译或交叉编译等方面更具有优势。中间表示还有助于支持高级编译器优化,大多数优化都是在这种代码形式上进行的。
机器代码
在计算机编程中,机器代码是由机器语言指令组成的计算机代码,这些指令用于控制计算机的中央处理器。机器代码是计算机程序的二进制表示形式,由计算机读取和执行。机器代码程序由一系列机器指令组成,每条指令都会使CPU执行一个非常具体的任务,例如加载、存储、跳转或在CPU的寄存器或内存中对一个或多个数据单元进行算术逻辑单元(ALU)操作。
指令集
在计算机科学中,指令集体系结构(ISA)是计算机抽象模型的一部分,通常定义了软件如何控制CPU。通常,ISA 定义了支持的指令、数据类型、寄存器、管理主内存的硬件支持、基本特性(如内存一致性、寻址模式、虚拟内存)以及 ISA 的一系列实现的输入/输出模型。
早期的 CPU 有特定的机器代码,可能会在每次发布新的 CPU 时破坏向前兼容性。指令集架构(ISA)定义并指定了系统指令集在内存中的行为和编码,而不指定其确切的实现。这充当了一个抽象层,使得同一系列CPU之间能够兼容,因此根据该系列的ISA编写或生成的机器代码将在该系列的所有 CPU 上运行,包括未来的CPU。因此可以用更低成本、更低性能的机器替换更高成本、更高性能的机器,而无需更换软件。这还使得该 ISA 实现的微架构能够发展,以便新的、更高性能的ISA实现能够运行在先前实现上运行的软件。
通常,每个架构系列(例如x86,ARM)都有自己的ISA,因此也有自己特定的机器代码语言。
程序二进制接口 (ABI)
在计算机软件中,应用程序二进制接口(ABI)是两个二进制程序模块之间的接口。通常,这些模块之一是库或操作系统功能,另一个是用户正在运行的程序。ABI 描述了应用程序和操作系统之间目标代码,平台上的编译器之间的调用约定,这是一种底层、依赖于硬件的格式。通常操作系统会为不同的 ISA 维护一套特有的 ABI。
Go 编译器编译步骤
代码基于此 Go 版本源码分析: go1.21.6 darwin/arm64
源文件解析
在编译的第一阶段,对源代码进行标记化(词法分析)、解析(语法分析),并为每个源文件构建语法树。每个语法树都是各自源文件的精确表示,其节点与源代码的各种元素(如表达式、声明和语句)相对应。语法树还包括位置信息,用于错误报告和创建调试信息。
cmd/compile/internal/syntax(Go 源码解析器)
词法分析
Go 语言的词法解析是通过 scanner 结构体实现的,这个结构体会持有当前扫描的数据源文件、启用的模式和当前被扫描到的 Token 等信息:
type scanner struct {
source
mode uint
nlsemi bool // if set '\n' and EOF translate to ';'
// current token, valid after calling next()
line, col uint
blank bool // line is blank up to col
tok token
lit string // valid if tok is _Name, _Literal, or _Semi ("semicolon", "newline", or "EOF"); may be malformed if bad is true
bad bool // valid if tok is _Literal, true if a syntax error occurred, lit may be malformed
kind LitKind // valid if tok is _Literal
op Operator // valid if tok is _Operator, _Star, _AssignOp, or _IncOp
prec int // valid if tok is _Operator, _Star, _AssignOp, or _IncOp
}
Go 语言中支持的全部 Token 类型都在 tokens.go 中定义,包括,所有的 token 类型都用特定正整数表示,你可以在这个文件中找到一些常见 Token 的定义,包括分别是名称和字面量、操作符、分隔符和关键字等:
const (
_ token = iota
_EOF // EOF
// names and literals
_Name // name
_Literal // literal
// operators and operations
// _Operator is excluding '*' (_Star)
_Operator // op
_AssignOp // op=
...
// delimiters
_Lparen // (
_Lbrack // [
...
// keywords
_Break // break
_Case // case
...
// empty line comment to exclude it from .String
tokenCount //
)
词法分析主要是由 scanner 结构体中的 next 方法驱动。scanner 每次都会通过 nextch 函数获取文件中最近的未被解析的字符,然后根据当前字符的不同执行不同的 case。例如:遇到了空格和换行符这些空白字符会直接跳过,遇到数字字符则会尝试匹配一个数字等。
// next advances the scanner by reading the next token.
//
// If a read, source encoding, or lexical error occurs, next calls
// the installed error handler with the respective error position
// and message. The error message is guaranteed to be non-empty and
// never starts with a '/'. The error handler must exist.
//
// If the scanner mode includes the comments flag and a comment
// (including comments containing directives) is encountered, the
// error handler is also called with each comment position and text
// (including opening /* or // and closing */, but without a newline
// at the end of line comments). Comment text always starts with a /
// which can be used to distinguish these handler calls from errors.
//
// If the scanner mode includes the directives (but not the comments)
// flag, only comments containing a //line, /*line, or //go: directive
// are reported, in the same way as regular comments.
func (s *scanner) next() {
nlsemi := s.nlsemi
s.nlsemi = false
redo:
// skip white space
s.stop()
startLine, startCol := s.pos()
for s.ch == ' ' || s.ch == '\t' || s.ch == '\n' && !nlsemi || s.ch == '\r' {
s.nextch()
}
// token start
s.line, s.col = s.pos()
s.blank = s.line > startLine || startCol == colbase
s.start()
if isLetter(s.ch) || s.ch >= utf8.RuneSelf && s.atIdentChar(true) {
s.nextch()
s.ident()
return
}
switch s.ch {
case -1:
if nlsemi {
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF
case '\n':
s.nextch()
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9':
s.number(false)
......
default:
s.errorf("invalid character %#U", s.ch)
s.nextch()
goto redo
}
return
assignop:
if s.ch == '=' {
s.nextch()
s.tok = _AssignOp
return
}
s.tok = _Operator
}
语法分析
Go 语言的解析器使用了 LALR(1) 的文法来解析词法分析过程中输出的 Token 序列,最右推导加向前查看是 Go 语言解析器的最基本原理。每个 Go 源代码文件最终都会被解析成一个独立的抽象语法树,所以语法树最顶层的结构或者开始符号都是 SourceFile:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
从 SourceFile 相关的解析规则我们可以看出,每一个文件都包含一个 package 的定义以及可选的 import 声明和其他的顶层声明(TopLevelDecl),每一个 SourceFile 在编译器中都对应一个 File 结构体。
// package PkgName; DeclList[0], DeclList[1], ...
type File struct {
Pragma Pragma
PkgName *Name
DeclList []Decl
EOF Pos
GoVersion string
node
}
语法解析入口函数,fileOrNil 方法开启对当前文件的词法和语法解析:
// cmd/compile/internal/syntax/syntax.go
// Parse parses a single Go source file from src and returns the corresponding
// syntax tree. If there are errors, Parse will return the first error found,
// and a possibly partially constructed syntax tree, or nil.
//
// If errh != nil, it is called with each error encountered, and Parse will
// process as much source as possible. In this case, the returned syntax tree
// is only nil if no correct package clause was found.
// If errh is nil, Parse will terminate immediately upon encountering the first
// error, and the returned syntax tree is nil.
//
// If pragh != nil, it is called with each pragma encountered.
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil {
if err, ok := p.(Error); ok {
first = err
return
}
panic(p)
}
}()
var p parser
p.init(base, src, errh, pragh, mode)
p.next()
return p.fileOrNil(), p.first
}
// ParseFile behaves like Parse but it reads the source from the named file.
func ParseFile(filename string, errh ErrorHandler, pragh PragmaHandler, mode Mode) (*File, error) {
f, err := os.Open(filename)
if err != nil {
if errh != nil {
errh(err)
}
return nil, err
}
defer f.Close()
return Parse(NewFileBase(filename), f, errh, pragh, mode)
}
// cmd/compile/internal/syntax/parser.go
// Package files
//
// Parse methods are annotated with matching Go productions as appropriate.
// The annotations are intended as guidelines only since a single Go grammar
// rule may be covered by multiple parse methods and vice versa.
//
// Excluding methods returning slices, parse methods named xOrNil may return
// nil; all others are expected to return a valid non-nil node.
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File
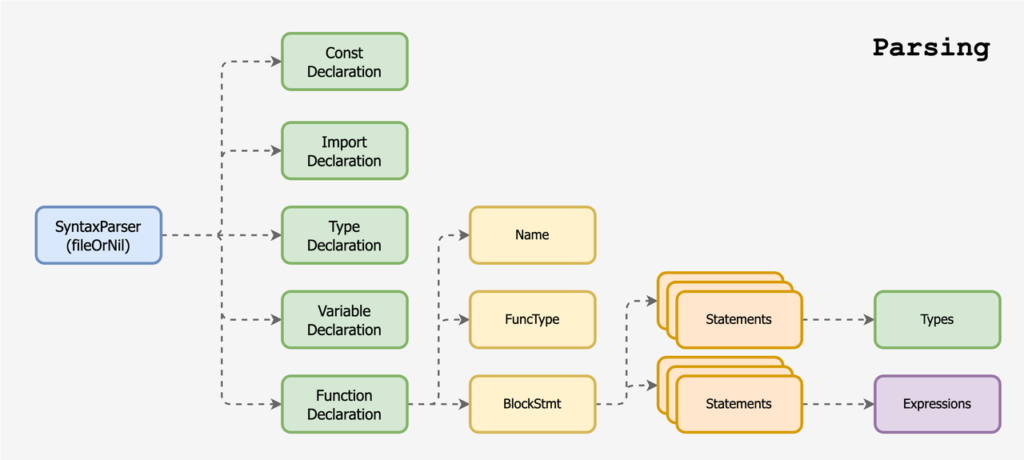
Go 共定义了下列五种大类,用于应对不同场景的解析,Declarations, Expressions, Types, Statements, Comments。其中顶层声明定义 (Decl) 有五大类型,分别是常量、类型、变量、函数和方法。表达式定义 (Expr) 有 KeyValue, Selector, Index, Assert 等。类型定义 (Type) 则有 Slice, Struct, Interface, Func 等。语句定义 (Stmt) 则有 Call, Branch, Assign, Switch 等。还有就是注释定义,
解析注释内容并标记注释所在位置。
// NameList
// NameList = Values
// NameList Type = Values
ConstDecl struct {
Group *Group // nil means not part of a group
Pragma Pragma
NameList []*Name
Type Expr // nil means no type
Values Expr // nil means no values
decl
}
// Name Type
TypeDecl struct {
Group *Group // nil means not part of a group
Pragma Pragma
Name *Name
TParamList []*Field // nil means no type parameters
Alias bool
Type Expr
decl
}
// NameList Type
// NameList Type = Values
// NameList = Values
VarDecl struct {
Group *Group // nil means not part of a group
Pragma Pragma
NameList []*Name
Type Expr // nil means no type
Values Expr // nil means no values
decl
}
// func Name Type { Body }
// func Name Type
// func Receiver Name Type { Body }
// func Receiver Name Type
FuncDecl struct {
Pragma Pragma
Recv *Field // nil means regular function
Name *Name
TParamList []*Field // nil means no type parameters
Type *FuncType
Body *BlockStmt // nil means no body (forward declaration)
decl
}
例如一个最简单的 Hello World 源码,会被解析成下列 AST:
package main
import "fmt"
func Hello() {
fmt.Println("Hello World")
}
{
"Pragma": null,
"PkgName": { "Value": "main" },
"DeclList": [
{
"Group": null,
"Pragma": null,
"LocalPkgName": null,
"Path": { "Value": "\"fmt\"", "Kind": 4, "Bad": false }
},
{
"Pragma": null,
"Recv": null,
"Name": { "Value": "Hello" },
"TParamList": null,
"Type": { "ParamList": null, "ResultList": null },
"Body": {
"List": [
{
"X": {
"Fun": { "X": { "Value": "fmt" }, "Sel": { "Value": "Println" } },
"ArgList": [
{ "Value": "\"Hello World\"", "Kind": 4, "Bad": false }
],
"HasDots": false
}
}
],
"Rbrace": {}
}
}
],
"EOF": {},
"GoVersion": ""
}
类型检查
当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对整棵抽象语法树的遍历,我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口是否完整实现等。
cmd/compile/internal/types2(类型检查)
// cmd/compile/internal/types2/api.go
// Check type-checks a package and returns the resulting package object and
// the first error if any. Additionally, if info != nil, Check populates each
// of the non-nil maps in the Info struct.
//
// The package is marked as complete if no errors occurred, otherwise it is
// incomplete. See Config.Error for controlling behavior in the presence of
// errors.
//
// The package is specified by a list of *syntax.Files and corresponding
// file set, and the package path the package is identified with.
// The clean path must not be empty or dot (".").
func (conf *Config) Check(path string, files []*syntax.File, info *Info) (*Package, error) {
pkg := NewPackage(path, "")
return pkg, NewChecker(conf, pkg, info).Files(files)
}
func (check *Checker) checkFiles(files []*syntax.File) (err error) {
...
print("== initFiles ==")
check.initFiles(files)
print("== collectObjects ==")
check.collectObjects()
print("== packageObjects ==")
check.packageObjects()
...
}
以上几个函数会针对不同的 Declearations 进行类型检查,最终生成 types2.Package 数据结构。
中间代码生成(IR Construction)
IR 抽象语法树构建
cmd/compile/internal/types(编译器使用的类型)cmd/compile/internal/ir(编译器使用的 AST)cmd/compile/internal/noder(构建编译器专用 AST)
编译器会将经过类型检查的代码转换编译器专用的抽象语法树。
关键代码
// cmd/compile/internal/noder/noder.go
func LoadPackage(filenames []string) {
base.Timer.Start("fe", "parse")
// Limit the number of simultaneously open files.
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
noders := make([]*noder, len(filenames))
for i := range noders {
p := noder{
err: make(chan syntax.Error),
}
noders[i] = &p
}
// Move the entire syntax processing logic into a separate goroutine to avoid blocking on the "sem".
go func() {
for i, filename := range filenames {
filename := filename
p := noders[i]
sem <- struct{}{}
go func() {
defer func() { <-sem }()
defer close(p.err)
fbase := syntax.NewFileBase(filename)
f, err := os.Open(filename)
if err != nil {
p.error(syntax.Error{Msg: err.Error()})
return
}
defer f.Close()
// 针对每一个编译的源文件进行词法和语法分析
p.file, _ = syntax.Parse(fbase, f, p.error, p.pragma, syntax.CheckBranches) // errors are tracked via p.error
}()
}
}()
var lines uint
var m posMap
for _, p := range noders {
for e := range p.err {
base.ErrorfAt(m.makeXPos(e.Pos), 0, "%s", e.Msg)
}
if p.file == nil {
base.ErrorExit()
}
lines += p.file.EOF.Line()
}
base.Timer.AddEvent(int64(lines), "lines")
// 生成统一 IR
unified(m, noders)
}
func unified(m posMap, noders []*noder) {
inline.InlineCall = unifiedInlineCall
typecheck.HaveInlineBody = unifiedHaveInlineBody
// 1. 类型检查
// 2. 解析经过类型检查的源文件的定义
// 3. 输出包定义(文本类型)
data := writePkgStub(m, noders)
// We already passed base.Flag.Lang to types2 to handle validating
// the user's source code. Bump it up now to the current version and
// re-parse, so typecheck doesn't complain if we construct IR that
// utilizes newer Go features.
base.Flag.Lang = fmt.Sprintf("go1.%d", goversion.Version)
types.ParseLangFlag()
target := typecheck.Target
typecheck.TypecheckAllowed = true
// 解析先前输出的源文件的定义
localPkgReader = newPkgReader(pkgbits.NewPkgDecoder(types.LocalPkg.Path, data))
readPackage(localPkgReader, types.LocalPkg, true)
r := localPkgReader.newReader(pkgbits.RelocMeta, pkgbits.PrivateRootIdx, pkgbits.SyncPrivate)
// IR 构建
r.pkgInit(types.LocalPkg, target)
// Type-check any top-level assignments. We ignore non-assignments
// here because other declarations are typechecked as they're
// constructed.
// 类型检查顶层赋值语句,其他语句的类型检查已在先前构建过程中完成。
for i, ndecls := 0, len(target.Decls); i < ndecls; i++ {
switch n := target.Decls[i]; n.Op() {
case ir.OAS, ir.OAS2:
target.Decls[i] = typecheck.Stmt(n)
}
}
// 将构建好的 IR 写入 Target
readBodies(target, false)
...
}
// writePkgStub type checks the given parsed source files,
// writes an export data package stub representing them,
// and returns the result.
func writePkgStub(m posMap, noders []*noder) string {
// 类型检查
pkg, info := checkFiles(m, noders)
pw := newPkgWriter(m, pkg, info)
// 解析源文件中的定义
pw.collectDecls(noders)
publicRootWriter := pw.newWriter(pkgbits.RelocMeta, pkgbits.SyncPublic)
privateRootWriter := pw.newWriter(pkgbits.RelocMeta, pkgbits.SyncPrivate)
assert(publicRootWriter.Idx == pkgbits.PublicRootIdx)
assert(privateRootWriter.Idx == pkgbits.PrivateRootIdx)
{
w := publicRootWriter
w.pkg(pkg)
w.Bool(false) // TODO(mdempsky): Remove; was "has init"
scope := pkg.Scope()
names := scope.Names()
w.Len(len(names))
for _, name := range names {
w.obj(scope.Lookup(name), nil)
}
w.Sync(pkgbits.SyncEOF)
w.Flush()
}
{
w := privateRootWriter
w.pkgInit(noders)
w.Flush()
}
var sb strings.Builder
// dump 到字符串中
pw.DumpTo(&sb)
// At this point, we're done with types2. Make sure the package is
// garbage collected.
freePackage(pkg)
return sb.String()
}
转换过程
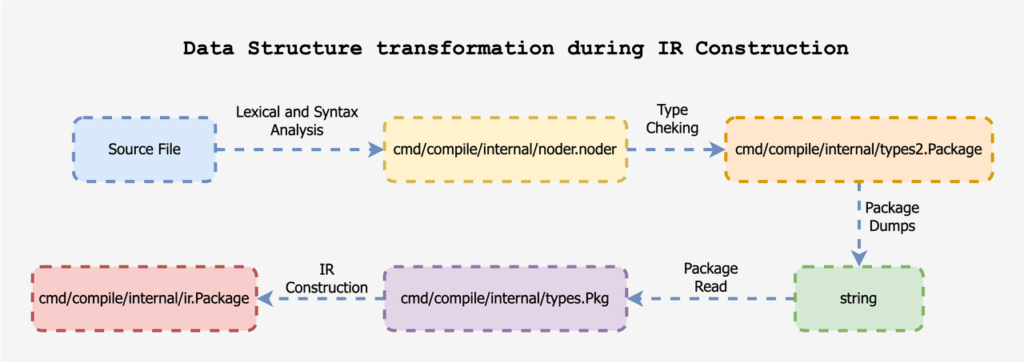
IR 优化
什么是去虚化?
对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化(devirtualize),即转换为一个或多个直接调用用,然后才能进行方法内联。
对中间代码进行下列优化:
- 消除未使用(“死”)代码:
cmd/compile/internal/deadcode - 去虚拟化:
cmd/compile/internal/devirtualize - 函数调用内联:
cmd/compile/internal/inline - 内存逃逸分析:
cmd/compile/internal/escape
遍历和替换
遍历和替换将内部表示中复杂的语句分解为单个的、更简单的语句,引入临时变量,并遵守计算顺序。这个替换的过程是通过 cmd/compile/internal/walk 包中相关函数实现的,这里简单展示几个函数的签名:
// cmd/compile/internal/walk/builtin.go
func walkExpr(n ir.Node, init *ir.Nodes) ir.Node
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node
// walkExpr, walkExpr1 会将不同的原生操作拆分成一条或多条简单语句。
// 返回拆分后的 ir.Node
func walkAppend(n *ir.CallExpr, init *ir.Nodes, dst ir.Node) ir.Node
func walkClear(n *ir.UnaryExpr) ir.Node
func walkClose(n *ir.UnaryExpr, init *ir.Nodes) ir.Node
func walkCopy(n *ir.BinaryExpr, init *ir.Nodes, runtimecall bool) ir.Node
func walkDelete(init *ir.Nodes, n *ir.CallExpr) ir.Node
func walkLenCap(n *ir.UnaryExpr, init *ir.Nodes) ir.Node
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node
func walkMakeMap(n *ir.MakeExpr, init *ir.Nodes) ir.Node
func walkMakeSlice(n *ir.MakeExpr, init *ir.Nodes) ir.Node
func walkMakeSliceCopy(n *ir.MakeExpr, init *ir.Nodes) ir.Node
func walkNew(n *ir.UnaryExpr, init *ir.Nodes) ir.Node
......
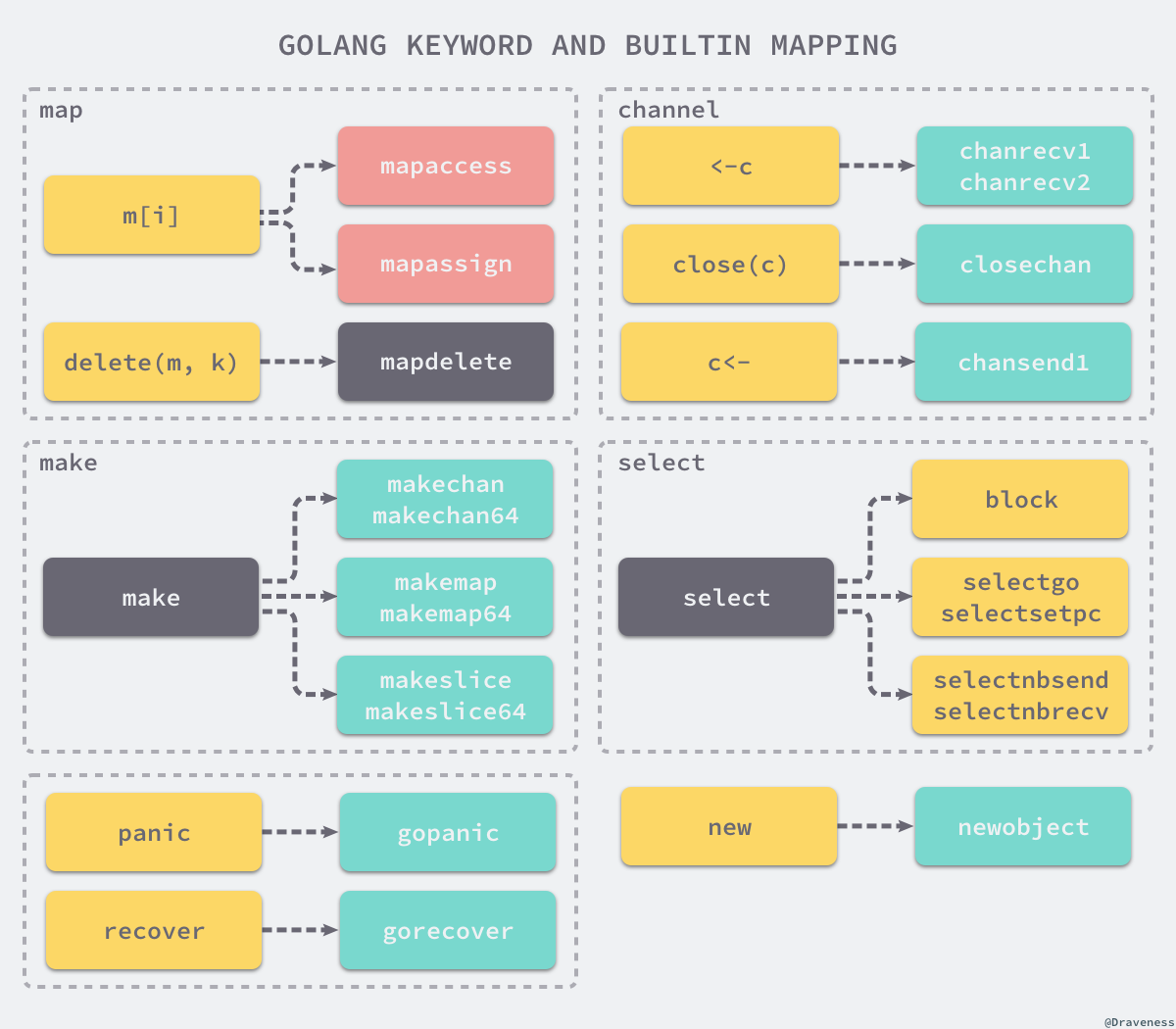
这些用于遍历抽象语法树的函数会将一些关键字和内建函数转换成函数调用。例如: 上述函数会将 panic、recover 两个内建函数转换成 runtime.gopanic 和 runtime.gorecover 两个真正运行时函数。
// cmd/compile/internal/walk/expr.go
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
...
case ir.OPANIC:
n := n.(*ir.UnaryExpr)
return mkcall("gopanic", nil, init, n.X)
case ir.ORECOVERFP:
return walkRecoverFP(n.(*ir.CallExpr), init)
...
}
}
// cmd/compile/internal/walk/builtin.go
// walkRecoverFP walks an ORECOVERFP node.
func walkRecoverFP(nn *ir.CallExpr, init *ir.Nodes) ir.Node {
return mkcall("gorecover", nn.Type(), init, walkExpr(nn.Args[0], init))
}
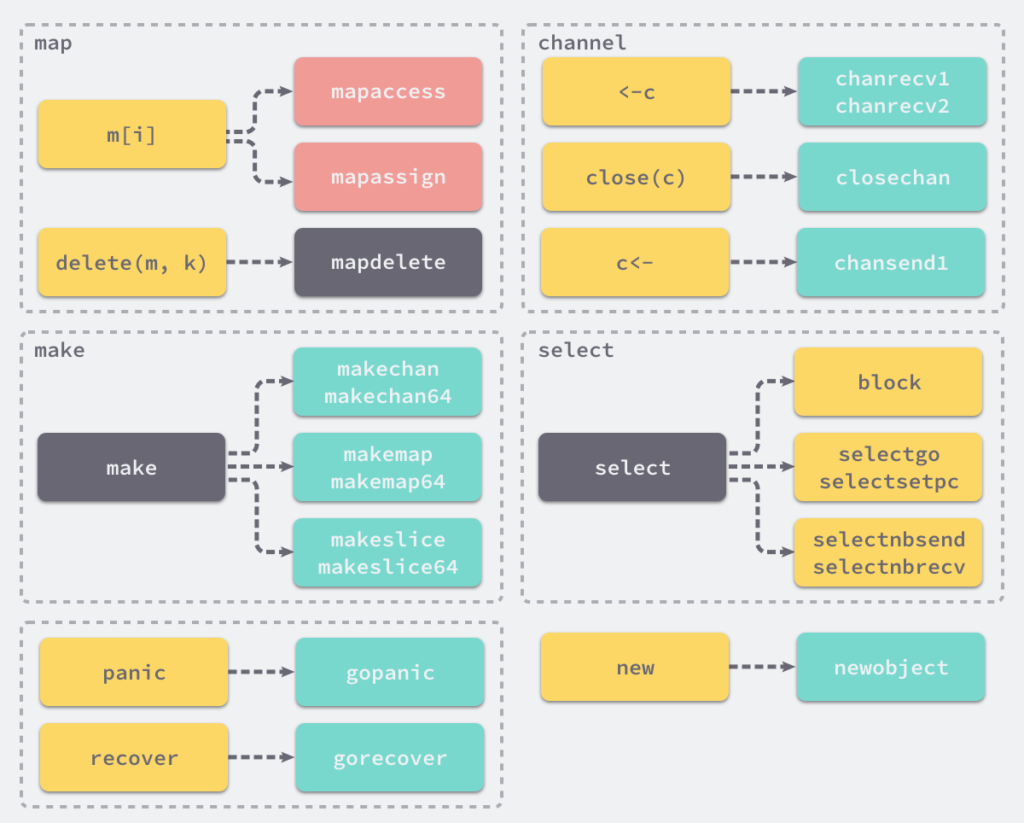
图片来源: https://img.draveness.me/2019-02-05-golang-keyword-and-builtin-mapping.png
SSA 生成
在这一阶段,IR AST 被转换为 SSA 形式,这是一种更低级的中间代码,其具有特定的属性,更容易进行优化,并最终生成机器代码。在这一转换过程中,会应用函数内联。编译器会根据具体情况,将这些特殊函数替换为经过大量优化的代码。
在将 AST 转换为 SSA 的过程中,某些节点也会被降级为更简单的组件,以便编译器的其他部分可以使用它们。例如,内置的 Copy 函数被 memmove 所取代,range 循环被改写为 for 循环。由于历史原因,其中一些转换规则在向 SSA 转换之前就被应用(上述 IR 优化过程中),但最终目标将会统一到 SSA 转换过程中。
然后,应用一系列与机器无关的优化规则。这些程序和规则与任何单一的计算机架构无关,因此可以在所有 GOARCH 上运行。这些优化规则包括消除死代码、删除不需要的空值检查以及删除未使用的分支。通用重写规则主要涉及表达式,例如用常量值替换某些表达式,以及优化乘法和浮点运算。
cmd/compile/internal/ssa(SSA 处理规则)cmd/compile/internal/ssagen(转换 AST 为 SSA)
示例
// Sources
package main
import "fmt"
func main() {
fmt.Println("Hello World")
}
我们可以使用 GOSSAFUNC 环境变量构建上述代码并获取从源代码到最终的中间代码经历的几十次迭代,其中所有的数据都存储到了 ssa.html 文件中:
$ GOSSAFUNC=main go build main.go
command-line-arguments
dumped SSA to ./ssa.html
上述文件中包含源代码对应的抽象语法树、几十个版本的中间代码以及最终生成的 SSA,下面是关键步骤的节选:
AST
buildssa-enter
buildssa-body
. DCL # main.go:6:13
. . NAME-fmt.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used SLICE-[]any tc(1) # main.go:6:13 print.go:313:14
. BLOCK # main.go:6:13
. BLOCK-List
. . AS tc(1) # main.go:6:13
. . . NAME-main..autotmp_8 esc(N) Class:PAUTO Offset:0 Addrtaken AutoTemp OnStack Used ARRAY-[1]any tc(1) # main.go:6:13
. . AS tc(1) # main.go:6:13
. . . NAME-main..autotmp_7 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used PTR-*[1]any tc(1) # main.go:6:13
. . . ADDR PTR-*[1]any tc(1) # main.go:6:13
. . . . NAME-main..autotmp_8 esc(N) Class:PAUTO Offset:0 Addrtaken AutoTemp OnStack Used ARRAY-[1]any tc(1) # main.go:6:13
. . BLOCK tc(1) # main.go:6:14
. . BLOCK-List
. . . AS tc(1) # main.go:6:14
. . . . INDEX Bounded any tc(1) # main.go:6:13
. . . . . DEREF Implicit ARRAY-[1]any tc(1) # main.go:6:13
. . . . . . NAME-main..autotmp_7 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used PTR-*[1]any tc(1) # main.go:6:13
. . . . . LITERAL-0 int tc(1) # main.go:6:13
. . . . EFACE any tc(1) # main.go:6:14
. . . . . ADDR PTR-*uint8 tc(1) # main.go:6:14
. . . . . . LINKSYMOFFSET-type:string Offset:0 uint8 tc(1)
. . . . . ADDR PTR-*string tc(1) # main.go:6:14
. . . . . . NAME-main..stmp_0 Class:PEXTERN Offset:0 Addrtaken Readonly Used string tc(1) # main.go:6:14
. . BLOCK tc(1) # main.go:6:14
. . BLOCK-List
. . . AS tc(1) # main.go:6:14
. . . . NAME-fmt.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used SLICE-[]any tc(1) # main.go:6:13 print.go:313:14
. . . . SLICEARR SLICE-[]any tc(1) # main.go:6:14
. . . . . NAME-main..autotmp_7 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used PTR-*[1]any tc(1) # main.go:6:13
. . BLOCK # main.go:6:13
. DCL # main.go:6:13
. . NAME-fmt.n esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # main.go:6:13 print.go:313:25
. AS tc(1) # main.go:6:13
. . NAME-fmt.n esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # main.go:6:13 print.go:313:25
. DCL # main.go:6:13
. . NAME-fmt.err esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used error tc(1) # main.go:6:13 print.go:313:32
. AS tc(1) # main.go:6:13
. . NAME-fmt.err esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used error tc(1) # main.go:6:13 print.go:313:32
. INLMARK # +main.go:6:13
. DCL # main.go:6:13 print.go:314:2
. . NAME-main..autotmp_3 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used int tc(1) # main.go:6:13 print.go:314:2
. DCL # main.go:6:13 print.go:314:2
. . NAME-main..autotmp_4 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. AS tc(1) # main.go:6:13 print.go:314:2
. . NAME-main..autotmp_6 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. BLOCK-init
. . CALLFUNC IsDDD Walked STRUCT-(int, error) tc(1) # main.go:6:13 print.go:314:17
. . . NAME-fmt.Fprintln Class:PFUNC Offset:0 Used FUNC-func(io.Writer, ...any) (int, error) tc(1) # print.go:302:6
. . CALLFUNC-Args
. . . EFACE io.Writer tc(1) # main.go:6:13 print.go:314:20
. . . . ADDR PTR-*uint8 tc(1) # main.go:6:13 print.go:314:20
. . . . . LINKSYMOFFSET-go:itab.*os.File,io.Writer Offset:0 uint8 tc(1)
. . . . NAME-os.Stdout Class:PEXTERN Offset:0 Used PTR-*os.File tc(1) # file.go:66:2
. . . NAME-fmt.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used SLICE-[]any tc(1) # main.go:6:13 print.go:313:14
. BLOCK # main.go:6:13 print.go:314:2
. BLOCK-List
. . AS # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_5 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used int tc(1) # main.go:6:13 print.go:314:2
. . . RESULT int tc(1) # main.go:6:13 print.go:314:2
. . AS # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_6 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. . . RESULT Index:1 error tc(1) # main.go:6:13 print.go:314:2
. BLOCK # main.go:6:13 print.go:314:2
. BLOCK-List
. . AS tc(1) # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_3 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used int tc(1) # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_5 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used int tc(1) # main.go:6:13 print.go:314:2
. . AS tc(1) # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_4 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. . . NAME-main..autotmp_6 esc(N) Class:PAUTO Offset:0 AutoTemp OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. BLOCK # main.go:6:13
. BLOCK-List
. . AS tc(1) # main.go:6:13
. . . NAME-fmt.n esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # main.go:6:13 print.go:313:25
. . . NAME-main..autotmp_3 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used int tc(1) # main.go:6:13 print.go:314:2
. . AS tc(1) # main.go:6:13
. . . NAME-fmt.err esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used error tc(1) # main.go:6:13 print.go:313:32
. . . NAME-main..autotmp_4 esc(no) Class:PAUTO Offset:0 AutoTemp InlLocal OnStack Used error tc(1) # main.go:6:13 print.go:314:2
. GOTO main..i0 tc(1) # main.go:6:13
. LABEL main..i0 # main.go:6:13
buildssa-exit
在经过一系列的优化和规则应用后,最终获得中间代码:
// genssa
# main.go
00000 (5) TEXT main.main(SB), ABIInternal
00001 (5) FUNCDATA $0, gclocals·g2BeySu+wFnoycgXfElmcg==(SB)
00002 (5) FUNCDATA $1, gclocals·EaPwxsZ75yY1hHMVZLmk6g==(SB)
00003 (5) FUNCDATA $2, main.main.stkobj(SB)
v22 00004 (+6) STP (ZR, ZR), main..autotmp_8-16(RSP)
v28 00005 (6) MOVD $type:string(SB), R5
v13 00006 (6) MOVD R5, main..autotmp_8-16(RSP)
v35 00007 (6) MOVD $main..stmp_0(SB), R5
v19 00008 (6) MOVD R5, main..autotmp_8-8(RSP)
# print.go
v34 00009 (+314) MOVD os.Stdout(SB), R1
v31 00010 (?) NOP
v14 00011 (314) MOVD $go:itab.*os.File,io.Writer(SB), R0
v17 00012 (314) MOVD $main..autotmp_8-16(RSP), R2
v26 00013 (314) MOVD $1, R3
v20 00014 (314) MOVD R3, R4
v36 00015 (314) PCDATA $1, $0
v36 00016 (314) CALL fmt.Fprintln(SB)
# main.go
b4 00017 (7) RET
00018 (?) END
关键代码
配置初始化
// cmd/compile/internal/gc/main.go
// Prepare for backend processing. This must happen before pkginit,
// because it generates itabs for initializing global variables.
ssagen.InitConfig()
func InitConfig() {
types_ := ssa.NewTypes()
if Arch.SoftFloat {
softfloatInit()
}
// Generate a few pointer types that are uncommon in the frontend but common in the backend.
// Caching is disabled in the backend, so generating these here avoids allocations.
_ = types.NewPtr(types.Types[types.TINTER]) // *interface{}
_ = types.NewPtr(types.NewPtr(types.Types[types.TSTRING])) // **string
_ = types.NewPtr(types.NewSlice(types.Types[types.TINTER])) // *[]interface{}
_ = types.NewPtr(types.NewPtr(types.ByteType)) // **byte
_ = types.NewPtr(types.NewSlice(types.ByteType)) // *[]byte
_ = types.NewPtr(types.NewSlice(types.Types[types.TSTRING])) // *[]string
_ = types.NewPtr(types.NewPtr(types.NewPtr(types.Types[types.TUINT8]))) // ***uint8
_ = types.NewPtr(types.Types[types.TINT16]) // *int16
_ = types.NewPtr(types.Types[types.TINT64]) // *int64
_ = types.NewPtr(types.ErrorType) // *error
types.NewPtrCacheEnabled = false
ssaConfig = ssa.NewConfig(base.Ctxt.Arch.Name, *types_, base.Ctxt, base.Flag.N == 0, Arch.SoftFloat)
ssaConfig.Race = base.Flag.Race
ssaCaches = make([]ssa.Cache, base.Flag.LowerC)
...
}
ssa.NewTypes()初始化ssa.Types结构体并调用types.NewPtr函数缓存指针类型信息,ssa.Types中存储了 Go 语言中基本类型对应的指针类型信息。- 连续调用
_ = types.NewPtr(...)将编译器前端少见但后端常用的指针类型初始化并缓存到类型缓存中。 ssa.NewConfig通过编译目标架构、ssa.Types、上下文信息等信息指定用于生成中间代码和机器码的函数,当前编译器使用的指针、寄存器大小、可用寄存器列表、掩码等编译选项。
整体流程
经过 walk 系列函数的处理之后,抽象语法树就不会改变了。即cmd/compile/internal/gc/main.go 在执行完逃逸分析和写屏障检查后,就会开始进行顶层函数的编译,也就开始了 SSA 的生成。
// cmd/compile/internal/gc/compile.go
// compileFunctions compiles all functions in compilequeue.
// It fans out nBackendWorkers to do the work
// and waits for them to complete.
func compileFunctions() {
...
var wg sync.WaitGroup
var compile func([]*ir.Func)
compile = func(fns []*ir.Func) {
wg.Add(len(fns))
for _, fn := range fns {
fn := fn
queue(func(worker int) {
ssagen.Compile(fn, worker)
compile(fn.Closures)
wg.Done()
})
}
}
...
compile(compilequeue)
compilequeue = nil
wg.Wait()
}
// cmd/compile/internal/ssagen/pgen.go
// Compile builds an SSA backend function,
// uses it to generate a plist,
// and flushes that plist to machine code.
// worker indicates which of the backend workers is doing the processing.
func Compile(fn *ir.Func, worker int) {
f := buildssa(fn, worker)
// Note: check arg size to fix issue 25507.
if f.Frontend().(*ssafn).stksize >= maxStackSize || f.OwnAux.ArgWidth() >= maxStackSize {
largeStackFramesMu.Lock()
largeStackFrames = append(largeStackFrames, largeStack{locals: f.Frontend().(*ssafn).stksize, args: f.OwnAux.ArgWidth(), pos: fn.Pos()})
largeStackFramesMu.Unlock()
return
}
pp := objw.NewProgs(fn, worker)
defer pp.Free()
genssa(f, pp)
...
}
// cmd/compile/internal/ssagen/ssa.go
// buildssa builds an SSA function for fn.
// worker indicates which of the backend workers is doing the processing.
func buildssa(fn *ir.Func, worker int) *ssa.Func {
name := ir.FuncName(fn)
...
s.f = ssa.NewFunc(&fe)
s.config = ssaConfig
s.f.Type = fn.Type()
s.f.Config = ssaConfig
s.f.Cache = &ssaCaches[worker]
s.f.Cache.Reset()
s.f.Name = name
...
// Convert the AST-based IR to the SSA-based IR
s.stmtList(fn.Enter)
s.zeroResults()
s.paramsToHeap()
s.stmtList(fn.Body)
...
// Main call to ssa package to compile function
ssa.Compile(s.f)
...
return s.f
}
ssaConfig 是先前配置初始化中创建的配置,随后的中间代码生成其实也分成两个阶段
// cmd/compile/internal/ssagen/ssa.go
// stmtList converts the statement list n to SSA and adds it to s.
func (s *state) stmtList(l ir.Nodes) {
for _, n := range l {
s.stmt(n)
}
}
第一阶段使用 stmtList 以及相关函数将先前步骤中构建的 IR 语法树基于 SSA 的中间代码,stmt 函数会根据 IR 语法树中节点类型进行操作映射。
// cmd/compile/internal/ssa/compile.go
// Compile is the main entry point for this package.
// Compile modifies f so that on return:
// - all Values in f map to 0 or 1 assembly instructions of the target architecture
// - the order of f.Blocks is the order to emit the Blocks
// - the order of b.Values is the order to emit the Values in each Block
// - f has a non-nil regAlloc field
func Compile(f *Func) {
// TODO: debugging - set flags to control verbosity of compiler,
// which phases to dump IR before/after, etc.
if f.Log() {
f.Logf("compiling %s\n", f.Name)
}
f.HTMLWriter.WritePhase("start", "start")
...
for _, p := range passes {
...
tStart := time.Now()
p.fn(f)
tEnd := time.Now()
}
...
}
第二阶段调用 ssa.Compile() 函数将编译规则依次应用,对 SSA 中间代码进行更新。所有的规则都能在先前示例中输出的 ssa.html 中可以看到对应规则应用后的变化。
IR 语法树到 SSA
上面提到 stmtList 函数调用stmt 函数会根据 IR 语法树中节点类型进行操作映射。
// stmt converts the statement n to SSA and adds it to s.
func (s *state) stmt(n ir.Node) {
...
switch n.Op() {
case ir.OBLOCK:
n := n.(*ir.BlockStmt)
s.stmtList(n.List)
// No-ops
case ir.ODCLCONST, ir.ODCLTYPE, ir.OFALL:
// Expression statements
case ir.OCALLFUNC:
n := n.(*ir.CallExpr)
if ir.IsIntrinsicCall(n) {
s.intrinsicCall(n)
return
}
fallthrough
case ir.OCALLINTER:
...
case ir.ODEFER:
...
case ir.OGO:
n := n.(*ir.GoDeferStmt)
s.callResult(n.Call.(*ir.CallExpr), callGo)
...
default:
s.Fatalf("unhandled stmt %v", n.Op())
}
从上面节选的代码中不难看出,函数调用、方法调用、使用 defer 或者 go 关键字时都会执行 callResult() 生成调用函数的 SSA 节点,这些在开发者看来不同的概念在编译器中都会被实现成静态的函数调用,上层的关键字和方法只是语言为开发者提供的语法糖:
// cmd/compile/internal/ssagen/ssa.go
func (s *state) callResult(n *ir.CallExpr, k callKind) *ssa.Value {
return s.call(n, k, false)
}
// Calls the function n using the specified call type.
// Returns the address of the return value (or nil if none).
func (s *state) call(n *ir.CallExpr, k callKind, returnResultAddr bool) *ssa.Value {
...
// call target
switch {
case k == callDefer:
aux := ssa.StaticAuxCall(ir.Syms.Deferproc, s.f.ABIDefault.ABIAnalyzeTypes(nil, ACArgs, ACResults)) // TODO paramResultInfo for DeferProc
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux)
case k == callGo:
aux := ssa.StaticAuxCall(ir.Syms.Newproc, s.f.ABIDefault.ABIAnalyzeTypes(nil, ACArgs, ACResults))
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux) // TODO paramResultInfo for NewProc
case closure != nil:
// rawLoad because loading the code pointer from a
// closure is always safe, but IsSanitizerSafeAddr
// can't always figure that out currently, and it's
// critical that we not clobber any arguments already
// stored onto the stack.
codeptr = s.rawLoad(types.Types[types.TUINTPTR], closure)
aux := ssa.ClosureAuxCall(callABI.ABIAnalyzeTypes(nil, ACArgs, ACResults))
call = s.newValue2A(ssa.OpClosureLECall, aux.LateExpansionResultType(), aux, codeptr, closure)
case codeptr != nil:
// Note that the "receiver" parameter is nil because the actual receiver is the first input parameter.
aux := ssa.InterfaceAuxCall(params)
call = s.newValue1A(ssa.OpInterLECall, aux.LateExpansionResultType(), aux, codeptr)
case callee != nil:
aux := ssa.StaticAuxCall(callTargetLSym(callee), params)
call = s.newValue0A(ssa.OpStaticLECall, aux.LateExpansionResultType(), aux)
if k == callTail {
call.Op = ssa.OpTailLECall
stksize = 0 // Tail call does not use stack. We reuse caller's frame.
}
default:
s.Fatalf("bad call type %v %v", n.Op(), n)
}
...
if returnResultAddr {
return s.resultAddrOfCall(call, 0, fp.Type)
}
return s.newValue1I(ssa.OpSelectN, fp.Type, 0, call)
}
SSA 规则应用
通过对以下编译规则依次应用,对 SSA 中间代码进行更新,涉及到大量的中间代码优化。包含了一些机器特定的修改,包括根据目标架构对代码进行改写等操作。
// list of passes for the compiler
var passes = [...]pass{
// TODO: combine phielim and copyelim into a single pass?
{name: "number lines", fn: numberLines, required: true},
{name: "early phielim", fn: phielim},
{name: "early copyelim", fn: copyelim},
{name: "early deadcode", fn: deadcode}, // remove generated dead code to avoid doing pointless work during opt
{name: "short circuit", fn: shortcircuit},
{name: "decompose user", fn: decomposeUser, required: true},
{name: "pre-opt deadcode", fn: deadcode},
{name: "opt", fn: opt, required: true}, // NB: some generic rules know the name of the opt pass. TODO: split required rules and optimizing rules
{name: "zero arg cse", fn: zcse, required: true}, // required to merge OpSB values
{name: "opt deadcode", fn: deadcode, required: true}, // remove any blocks orphaned during opt
...
}
机器码生成
cmd/compile/internal/ssa主要负责对 SSA 中间代码进行降级、执行架构特定的优化和重写。cmd/compile/internal/ssagen生成objw.Prog结构用于后续的指令转换。cmd/compile/internal/objw作为汇编器会将这些指令转换成机器码完成这次编译。
SSA 降级
SSA 降级是在中间代码生成的过程中完成的,lower 以及后面的阶段都属于 SSA 降级这一过程,这么多轮的处理会将 SSA 转换成机器特定的操作:
// list of passes for the compiler
var passes = [...]pass{
...
{name: "lower", fn: lower, required: true},
{name: "addressing modes", fn: addressingModes, required: false},
{name: "late lower", fn: lateLower, required: true},
{name: "lowered deadcode for cse", fn: deadcode}, // deadcode immediately before CSE avoids CSE making dead values live again
{name: "lowered cse", fn: cse},
{name: "elim unread autos", fn: elimUnreadAutos},
{name: "tighten tuple selectors", fn: tightenTupleSelectors, required: true},
{name: "lowered deadcode", fn: deadcode, required: true},
{name: "checkLower", fn: checkLower, required: true},
...
}
SSA 降级执行的第一个阶段就是 lower,通过调用 lower 函数,它会将 SSA 的中间代码转换成机器特定的指令:
// cmd/compile/internal/ssa/lower.go
// convert to machine-dependent ops.
func lower(f *Func) {
// repeat rewrites until we find no more rewrites
applyRewrite(f, f.Config.lowerBlock, f.Config.lowerValue, removeDeadValues)
}
// cmd/compile/internal/ssa/rewrite.go
func applyRewrite(f *Func, rb blockRewriter, rv valueRewriter, deadcode deadValueChoice) {
...
for {
...
// apply rewrite function
if rv(v) {
vchange = true
// If value changed to a poor choice for a statement boundary, move the boundary
if v.Pos.IsStmt() == src.PosIsStmt {
if k := nextGoodStatementIndex(v, j, b); k != j {
v.Pos = v.Pos.WithNotStmt()
b.Values[k].Pos = b.Values[k].Pos.WithIsStmt()
}
}
}
...
}
...
}
从上面的调用关系可以看出 applyRewrite 函数调用的 rv valueRewriter 是 Func 结构体 f 中的 Config.lowerValue 函数,对应的则是先前 SSA 生成配置初始化过程中根据编译目标架构指定的处理函数之一:
// cmd/compile/internal/ssa/config.go
// A Config holds readonly compilation information.
// It is created once, early during compilation,
// and shared across all compilations.
type Config struct {
arch string // "amd64", etc.
PtrSize int64 // 4 or 8; copy of cmd/internal/sys.Arch.PtrSize
RegSize int64 // 4 or 8; copy of cmd/internal/sys.Arch.RegSize
Types Types
lowerBlock blockRewriter // block lowering function, first round
lowerValue valueRewriter // value lowering function, first round
lateLowerBlock blockRewriter // block lowering function that needs to be run after the first round; only used on some architectures
lateLowerValue valueRewriter // value lowering function that needs to be run after the first round; only used on some architectures
...
}
该结构变量在初始化配置时根据编译目标架构指定:
// NewConfig returns a new configuration object for the given architecture.
func NewConfig(arch string, types Types, ctxt *obj.Link, optimize, softfloat bool) *Config {
switch arch {
case "amd64":
...
c.lowerBlock = rewriteBlockAMD64
c.lowerValue = rewriteValueAMD64
c.lateLowerBlock = rewriteBlockAMD64latelower
c.lateLowerValue = rewriteValueAMD64latelower
c.splitLoad = rewriteValueAMD64splitload
case "386":
...
c.lowerBlock = rewriteBlock386
c.lowerValue = rewriteValue386
c.splitLoad = rewriteValue386splitload
...
}
...
}
以 AMD64 处理器架构为例,最终会调用 rewriteBlockAMD64, rewriteValueAMD64, rewriteBlockAMD64latelower, rewriteValueAMD64latelower, rewriteValueAMD64splitload 等函数将 SSA 操作,映射到对应架构的指令上:
// cmd/compile/internal/ssa/rewriteAMD64.go
func rewriteValueAMD64(v *Value) bool {
switch v.Op {
case OpAMD64ADCQ:
return rewriteValueAMD64_OpAMD64ADCQ(v)
case OpAMD64ADCQconst:
return rewriteValueAMD64_OpAMD64ADCQconst(v)
case OpAMD64ADDL:
return rewriteValueAMD64_OpAMD64ADDL(v)
...
}
...
}
SSA 生成中介绍的 Compile 函数会调用 objw.NewProgs 函数创建一个新的 Progs 结构并将生成的 SSA 中间代码都存入新建的结构体中,我们在 SSA 生成中得到的 ssa.html 文件就包含最终的中间代码:
// cmd/compile/internal/ssagen/pgen.go
// Compile builds an SSA backend function,
// uses it to generate a plist,
// and flushes that plist to machine code.
// worker indicates which of the backend workers is doing the processing.
func Compile(fn *ir.Func, worker int) {
f := buildssa(fn, worker)
...
pp := objw.NewProgs(fn, worker)
defer pp.Free()
genssa(f, pp)
...
}
主要包含下列操作:
- 基础代码块输出
- 分支代码解析
- 跳转表地址解析
// genssa appends entries to pp for each instruction in f.
func genssa(f *ssa.Func, pp *objw.Progs) {
...
// Emit basic blocks
for i, b := range f.Blocks {
...
}
...
// Resolve branches, and relax DefaultStmt into NotStmt
for _, br := range s.Branches {
...
}
...
// Resolve jump table destinations.
for _, jt := range s.JumpTables {
...
}
...
}
从 SSA 生成示例中可以看出最终的中间代码已经和汇编非常相似了,下一步就是调用汇编器将 SSA 转换成汇编代码。
// Flush converts from pp to machine code.
func (pp *Progs) Flush() {
plist := &obj.Plist{Firstpc: pp.Text, Curfn: pp.CurFunc}
obj.Flushplist(base.Ctxt, plist, pp.NewProg, base.Ctxt.Pkgpath)
}
汇编器
Flushplist 函数调用特定架构的 Preprocess 和 Assemble 方法,对代码进行最后的预处理和汇编的处理。
func Flushplist(ctxt *Link, plist *Plist, newprog ProgAlloc, myimportpath string) {
...
// Turn functions into machine code images.
for _, s := range text {
mkfwd(s)
if ctxt.Arch.ErrorCheck != nil {
ctxt.Arch.ErrorCheck(ctxt, s)
}
linkpatch(ctxt, s, newprog)
ctxt.Arch.Preprocess(ctxt, s, newprog)
ctxt.Arch.Assemble(ctxt, s, newprog)
if ctxt.Errors > 0 {
continue
}
linkpcln(ctxt, s)
if myimportpath != "" {
ctxt.populateDWARF(plist.Curfn, s, myimportpath)
}
if ctxt.Headtype == objabi.Hwindows && ctxt.Arch.SEH != nil {
s.Func().sehUnwindInfoSym = ctxt.Arch.SEH(ctxt, s)
}
}
}
// LinkArch is the definition of a single architecture.
type LinkArch struct {
*sys.Arch
Init func(*Link)
ErrorCheck func(*Link, *LSym)
Preprocess func(*Link, *LSym, ProgAlloc)
Assemble func(*Link, *LSym, ProgAlloc)
Progedit func(*Link, *Prog, ProgAlloc)
SEH func(*Link, *LSym) *LSym
UnaryDst map[As]bool // Instruction takes one operand, a destination.
DWARFRegisters map[int16]int16
}
参考对应的结构体,可以发现,不同的架构指定了不同的预处理和汇编函数,如 amd64 架构的预处理和汇编函数是 cmd/internal/obj/x86/obj6.go 中的 preprocess 函数和 cmd/internal/obj/x86/asm6.go 中的 span6 函数:
// cmd/internal/obj/x86/obj6.go
var Linkamd64 = obj.LinkArch{
Arch: sys.ArchAMD64,
Init: instinit,
ErrorCheck: errorCheck,
Preprocess: preprocess,
Assemble: span6,
Progedit: progedit,
SEH: populateSeh,
UnaryDst: unaryDst,
DWARFRegisters: AMD64DWARFRegisters,
}
汇编器对汇编指令进行一系列处理后,最后将汇编指令以机器码的形式导出到文件中:
// cmd/compile/internal/gc/main.go
func Main(archInit func(*ssagen.ArchInfo)) {
// Write object data to disk.
base.Timer.Start("be", "dumpobj")
dumpdata()
base.Ctxt.NumberSyms()
dumpobj()
}
下面是编译过程导出的 plan9 汇编和指定平台编译后导出的汇编指令:
// Plan9 Assembly
// GOOS=linux GOARCH=amd64 go build -gcflags=-S main.go
main.main STEXT size=89 args=0x0 locals=0x40 funcid=0x0 align=0x0
0x0000 00000 (main.go:5) TEXT main.main(SB), ABIInternal, $64-0
0x0000 00000 (main.go:5) CMPQ SP, 16(R14)
0x0004 00004 (main.go:5) PCDATA $0, $-2
0x0004 00004 (main.go:5) JLS 82
0x0006 00006 (main.go:5) PCDATA $0, $-1
0x0006 00006 (main.go:5) PUSHQ BP
0x0007 00007 (main.go:5) MOVQ SP, BP
0x000a 00010 (main.go:5) SUBQ $56, SP
0x000e 00014 (main.go:5) FUNCDATA $0, gclocals·g2BeySu+wFnoycgXfElmcg==(SB)
0x000e 00014 (main.go:5) FUNCDATA $1, gclocals·EaPwxsZ75yY1hHMVZLmk6g==(SB)
0x000e 00014 (main.go:5) FUNCDATA $2, main.main.stkobj(SB)
0x000e 00014 (main.go:6) MOVUPS X15, main..autotmp_8+40(SP)
0x0014 00020 (main.go:6) LEAQ type:string(SB), DX
0x001b 00027 (main.go:6) MOVQ DX, main..autotmp_8+40(SP)
0x0020 00032 (main.go:6) LEAQ main..stmp_0(SB), DX
0x0027 00039 (main.go:6) MOVQ DX, main..autotmp_8+48(SP)
0x002c 00044 (print.go:314) MOVQ os.Stdout(SB), BX
0x0033 00051 (<unknown line number>) NOP
0x0033 00051 (print.go:314) LEAQ go:itab.*os.File,io.Writer(SB), AX
0x003a 00058 (print.go:314) LEAQ main..autotmp_8+40(SP), CX
0x003f 00063 (print.go:314) MOVL $1, DI
0x0044 00068 (print.go:314) MOVQ DI, SI
0x0047 00071 (print.go:314) PCDATA $1, $0
0x0047 00071 (print.go:314) CALL fmt.Fprintln(SB)
0x004c 00076 (main.go:7) ADDQ $56, SP
0x0050 00080 (main.go:7) POPQ BP
0x0051 00081 (main.go:7) RET
0x0052 00082 (main.go:7) NOP
0x0052 00082 (main.go:5) PCDATA $1, $-1
0x0052 00082 (main.go:5) PCDATA $0, $-2
0x0052 00082 (main.go:5) CALL runtime.morestack_noctxt(SB)
0x0057 00087 (main.go:5) PCDATA $0, $-1
0x0057 00087 (main.go:5) JMP 0
0x0000 49 3b 66 10 76 4c 55 48 89 e5 48 83 ec 38 44 0f I;f.vLUH..H..8D.
0x0010 11 7c 24 28 48 8d 15 00 00 00 00 48 89 54 24 28 .|$(H......H.T$(
0x0020 48 8d 15 00 00 00 00 48 89 54 24 30 48 8b 1d 00 H......H.T$0H...
0x0030 00 00 00 48 8d 05 00 00 00 00 48 8d 4c 24 28 bf ...H......H.L$(.
0x0040 01 00 00 00 48 89 fe e8 00 00 00 00 48 83 c4 38 ....H.......H..8
0x0050 5d c3 e8 00 00 00 00 eb a7 ]........
rel 2+0 t=23 type:string+0
rel 2+0 t=23 type:*os.File+0
rel 23+4 t=14 type:string+0
rel 35+4 t=14 main..stmp_0+0
rel 47+4 t=14 os.Stdout+0
rel 54+4 t=14 go:itab.*os.File,io.Writer+0
rel 72+4 t=7 fmt.Fprintln+0
rel 83+4 t=7 runtime.morestack_noctxt+0
// amd64 Targeted assembly
// go tool objdump -s main.main main > dumpobj.txt
TEXT main.main(SB) main.go
main.go:5 0x47ae20 493b6610 CMPQ SP, 0x10(R14)
main.go:5 0x47ae24 764c JBE 0x47ae72
main.go:5 0x47ae26 55 PUSHQ BP
main.go:5 0x47ae27 4889e5 MOVQ SP, BP
main.go:5 0x47ae2a 4883ec38 SUBQ $0x38, SP
main.go:6 0x47ae2e 440f117c2428 MOVUPS X15, 0x28(SP)
main.go:6 0x47ae34 488d15456d0000 LEAQ 0x6d45(IP), DX
main.go:6 0x47ae3b 4889542428 MOVQ DX, 0x28(SP)
main.go:6 0x47ae40 488d15e96f0300 LEAQ 0x36fe9(IP), DX
main.go:6 0x47ae47 4889542430 MOVQ DX, 0x30(SP)
print.go:314 0x47ae4c 488b1d15370a00 MOVQ os.Stdout(SB), BX
print.go:314 0x47ae53 488d056e740300 LEAQ go:itab.*os.File,io.Writer(SB), AX
print.go:314 0x47ae5a 488d4c2428 LEAQ 0x28(SP), CX
print.go:314 0x47ae5f bf01000000 MOVL $0x1, DI
print.go:314 0x47ae64 4889fe MOVQ DI, SI
print.go:314 0x47ae67 e8b4aeffff CALL fmt.Fprintln(SB)
main.go:7 0x47ae6c 4883c438 ADDQ $0x38, SP
main.go:7 0x47ae70 5d POPQ BP
main.go:7 0x47ae71 c3 RET
main.go:5 0x47ae72 e869fcfdff CALL runtime.morestack_noctxt.abi0(SB)
main.go:5 0x47ae77 eba7 JMP main.main(SB)

{kind=link}